我在《怎样把网站升级到http/2》介绍了升级到http/2的方法,并说明了http/2的优点:
- http头部压缩
- 多路复用
- Server Push
下面一一进行说明。
1. 头部压缩
为什么要进行头部压缩呢?我在《WebSocket与TCP/IP》说过:HTTP头是比较长的,如果发送的数据比较小时,也得发送一个很大的HTTP头部,如下图所示:

当这种请求数很多的时候,会导致网络的吞吐率不高。并且,比较大的HTTP头部会迅速占满慢启动过程中的拥塞窗口,导致延迟加大。所以HTTP头的压缩显得很有必要,HTTP/2的前身SPDY引入了deflate的压缩算法,但是据说这种容易受攻击,HTTP/2使用了新的压缩方法,在规范RFC 7541进行了说明。关于头部压缩,规范的附录举了个很生动的例子。这里用这个例子做为说明,解释可以怎么对HTTP头部进行压缩。
首先对常用的HTTP头部字段进行编号,用一个静态表格表示:
| Index | Header Name | Header Value |
|---|---|---|
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | status | 200 |
| 9 | status | 204 |
| … | … | … |
| 16 | accept-encoding | gzip, deflate |
| 17 | accept-language | |
| … | … | … |
| 61 | www-authenticate |
总共有61个,其中冒号开头的如:method是请求行里的,2就表示Method: POST,如果要表示Method: OPTION呢?用下面的表示:
0206OPTION
其中02表示在静态表格的索引index,查一下这个表格可知道2表示的Header Name为:method。接着的06表示method名的长度为6,后面紧接着就是字段的内容即method名为OPTION。那它怎么知道02后面跟着的06不是表示index为6的”:scheme http”的头字段呢?因为如果Header Name和Header Value都是用的这个表的,如Method POST表示为:
0x82
而不是02了,这里就是把第8位置成了1,变成了二进制的1000 0002,表示name/value完全匹配。而如果第8位不是1,如0000 0002那么value值就是自定义的,后面紧跟着的一个字节就是表示value的字符长度,然后再跟着相应长度的字符。
value字符是使用霍夫曼编码的,规范根据字符的使用频率高低定了一个编码表,这个编码表把常用的字符的大小控制在5 ~ 7位,比ASCII编码的8位要小一些。根据编码表:
| sym | code as bits | code as hex | len in bits |
|---|---|---|---|
| ‘O’ | 1101010 | 6a | 7 |
| ‘P’ | 1101011 | 6b | 7 |
| ‘T’ | 1101111 | 6f | 7 |
| ‘I’ | 1100100 | 64 | 7 |
| ‘N’ | 1101001 | 69 | 7 |
OPTION会被编码为:6a6b 6f64 6a69,所以Method: OPTION最终被编码为:
0206 6a6b 6f64 6a69
一共是8个字节,原先用字符串需要14个字节。
还有,如果有多次请求,后面的请求有一些头部字段和前面的一样,那么会用一个动态表格维护相同的头部字段。如果name/value是在上面说的静态表格都有的就不会保存到动态表格。动态表格可以用一个栈或者动态数组来存储。
例如,第一次请求头部字段”Method: OPTION”在静态表格没有,它会被压到一个栈里面去,此时栈只有一个元素,用索引为62 = 61 + 1表示这个字段,在接下来的第二次、第三次请求如果用到了这个字段就用index为62表示,即遇到了62就表示Method: OPTION。如果又有其它一个自定义字段被压到这个栈里面,这个字段的索引就为62,而Method: OPTION就变成了63,越临近压进去的编号就越往前。
静态表格的index是从1开始,动态表格是从62开始,而index为0的表示自定义字段名,用key长度 + key + value长度 + value表示,当把它这个自定义字段压到动态表格里面之后,它就有index了。当然,可以控制是否需要把字段压到动态表格里面,通过设定标志位,这里不展开说明。
这个算法叫做HPACK,更详细的过程可以查看RFC 7541:HPACK: Header Compression for HTTP/2(可以直接拉到最后面看例子)。
Chrome是在src/net/http2/hpack这个目录做的头部解析,静态表格是在这个文件hpack_static_table_entries,如下图所示:

根据文档,动态表格默认最多的字段数为4096:
|
1 2 3 |
// The last received DynamicTableSizeUpdate value, initialized to // SETTINGS_HEADER_TABLE_SIZE. size_t size_limit_ = 4096; // Http2SettingsInfo::DefaultHeaderTableSize(); |
可在传输过程中动态改变,受对方能力的限制,因为不仅是存自己请求的字段,还要有一个表格存对方响应的字段。
Chrome里的动态表格是用一个向量vector的数据结构表示的:
|
1 |
const std::vector<HpackStringPair>* const table_; |
vector就是C++里面的动态数组。每次插入的时候就在数组前面插入:
|
1 |
table_.push_front(entry); |
而查找的时候,直接用数组的索引去定位,下面是查找动态数组的:
|
1 2 3 4 5 6 7 |
// Lookup函数 index -= kFirstDynamicTableIndex; // kFirstDynamicTableIndex等于62 if (index < table_.size()) { const HpackDecoderTableEntry& entry = table_[index]; return entry; } return nullptr; |
头部压缩最主要的内容就说到这里了,接下来说一下更为厉害的多路复用。
2. 多路复用
传统的HTTP/1.1为了提高并发性,得通过提高连接数,即同时多发几个请求,因为一个连接只能发一个请求,所以需要多建立几个TCP连接。建立TCP连接需要线程开销,我们知道Chrome同一个域最多同时只能建立6个连接。所以就有了雪碧图、合并代码文件等减少请求数的解决方案。
在HTTP/2里面,一个域只需要建立一次TCP连接就可以传输多个资源。多个数据流/信号通过一条信道进行传输,充分地利用高速信道,就叫多路复用(Multiplexing)。
在HTTP/1.1里面,一个资源通过一个TCP连接传输,一个大的资源可能会被拆成多个TCP报文段,每个报文段都有它的编号,按照从前往后依次增大的顺序,接收方把收到的报文段按照顺序依次拼接,就得到了完整的资源。当然,这个是TCP传输自然的特性,和HTTP/1.1没有直接关系。
那么怎么用一个连接传输多个资源呢?HTTP/2把每一个资源的传输叫做流Stream,每个流都有它的唯一编号stream id,一个流又可能被拆成多个帧Frame,每个帧按照顺序发送,TCP报文的编号可以保证后发送的帧的顺序比先发送的大。在HTTP/1.1里面同一个资源顺序是依次连续增大的,因为只有一个资源,而在HTTP/2里面它很可能是离散变大的,中间会插着发送其它流的帧,但只要保证每个流按顺序拼接就好了。如下图所示:

为什么叫它流呢,因为数据就像水流一样会流动,所以叫它为流/数据流,流的特点是有序的,它是数据的一个序列。它可以从键盘传到内存,再由内存传输到硬盘,或者传输到服务端。
在通信里面,流被分成若干帧,HTTP/2规定了11种类型的帧,包括HEADERS/DATA/SETTINGS等,HEADERS是用来传输http头部的,DATA是用来发送请求/响应数据的,SETTINGS是在传输过程中用来做控制的。一个帧的格式如下图所示:

帧的头部有9个字节,前3个字节(24位)表示帧有效数据(Frame Payload)的长度,所以每个帧最大能传送的数据为2 ^ 24 = 16MB,但标准规定默认最大为2 ^ 14 = 16Kb,除非双方通过settings帧进行控制。第4个字节Type表示帧类型,如0x0表示data,0x1是headers,0x4是settings。Flags是每种帧用来控制一些参数的标志位,如在data帧里面第一个标志位打开0x1是表示END_STREAM,即当前数据帧是当前流的最后一个数据帧。Stream Identifier是流的标志符即流的编号,它的首位R是保留位(留着以后用)。最后就是Payload,当前帧的有效负载。
每个请求都会创建一个流,每个流的创建都是请求方通过发送头部帧,即头部帧用来打开一个流,每个流都有它的优先级,放在头部帧里面。流的头部帧还包含了上面第1点提到的HTTP压缩头部字段。
每个流都有一个半关闭的状态,当一方收到END_STREAM的时候,当前流就处于半关闭(remote)的状态,这个时候另一方不再发送数据了,当前方也发一个END_STREAM给对方的时候,这个时候流就处于完全关闭的状态。已关闭的流的编号在当前连接不能复用,避免在新的流收到延迟的相同编号的老的流的帧。所以流的编号是递增的。
更详细的描述可以参考这个文档:Hypertext Transfer Protocol Version 2 (HTTP/2)。
我们以访问Walking Dog这个页面做为说明,看一下流和帧是怎么传输的,这个页面总共加载13个资源:
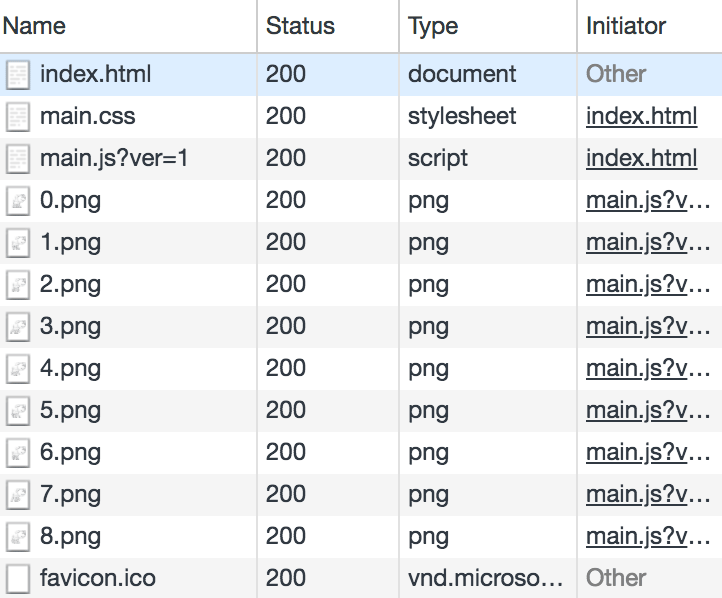
包括index.html、main.js、main.css和10张图片。
Chrome解码HTTP/2帧的目录在src/net/http2,而编码的目录在src/net/spdy。
所谓解码就是按照格式解析接收到的http/2的帧,在Chrome里面通过打印Log观察这个过程,如下代码示例:
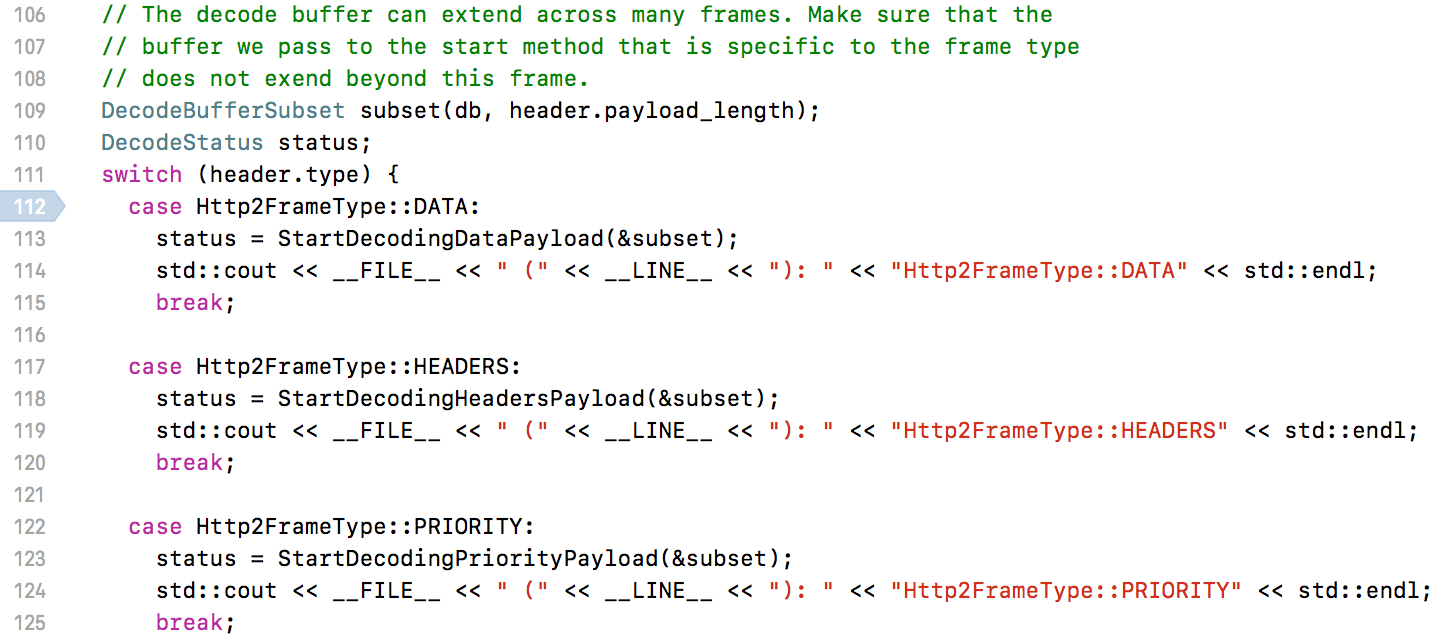
按照打印的顺序一一说明:
(1)SETTINGS(stream_id = 0; flags = 0; length = 18)
先是收到了一个SETTINGS的帧,payload内容为:
parameter=MAX_CONCURRENT_STREAMS(0x3), value=128
parameter=INITIAL_WINDOW_SIZE(0x4), value=65536
parameter=MAX_FRAME_SIZE(0x5), value=16777215
另一方即服务端(nginx)设置了max_concurrent_streams为128,表示stream的最多并发数为128,即同时最多只能有128个请求。window_size是用来做流控制(Flow Control)的,表示对方接收的缓冲容量,分为全局的缓冲容量和单个流的缓冲容量,如果stream_id为0则表示全局,如果非0的话则是相应stream,上面服务设置初始化的window size为64KB,在发送过程中可能会调整这个值,当接收方的缓存空间满了可能会置为0发给对方告诉对方不要再给我发了,这个和TCP的拥塞窗口很像,但是这个是在应用层做的控制,可以方便对每个流的接收进行控制,例如当缓存空间不足时,优先级高的流可能给的window_size会更大一点。max_frame_size表示每个帧的payload最大值,这里设置成了最大值16MB。与此同时浏览器也给服务发了自己的settings。如果settings不是使用的标准规定的默认值,那么就会传递settings帧。
然后收到了第二帧:
(2)WINDOW_UPDATE (stream id = 0; flag = 0; length = 4)
window_update类型的帧是用于更新window_size的,payload内容为:
window_size_increment=2147418112
这里把window_size设置成了最大值2GB,在第一帧里的max_frame_size也是最大值,可以说明服务没有限制接收速度。这里的stream id为0也是表示这个配置是全局的。
那为什么不直接初始化的时候直接设置window_size呢,实现上就是这样的。可以对比一下,在连谷歌的gstatic.com的时候收到的帧是这样的:
INITIAL_WINDOW_SIZE, value=1048576
MAX_HEADER_LIST_SIZE, value=16384
window_size_increment=983041
这样看起来比较合理一点(另外它还设置了header头部字段数最大值)。
在Chrome源码里面我只看到了一个地方使用到了window size,那就是当对方的window size为0时,流就会排队:
|
1 2 3 |
if (session_->IsSendStalled() || send_window_size_ <= 0) { return Requeue; } |
而通过nginx源码,我们发现nginx会在每发送一个帧的时候window size就会减掉当前帧大小:
|
1 2 3 |
ngx_http_v2_queue_frame(h2c, frame); h2c->send_window -= frame_size; stream->send_window -= frame_size; |
发送成功后进行cleanup又会把它加回来,如果send_window变成0,就会进行排队。
(3)SETTINGS (stream id = 0; flag = 1; length = 0)
第三帧也是settings,但是这次没有内容,长度为0,设置flag为1表示ACK,表示认同浏览器给它发的SETTINGS。flags在不同类型的帧有不同的含义,如下代码所示:
|
1 2 3 4 5 6 7 |
enum Http2FrameFlag { END_STREAM = 0x01, // DATA, HEADERS 表示当前流结束 ACK = 0x01, // SETTINGS, PING settings表示接受对方的设置,而ping是用来协助对方测量往返时间的 END_HEADERS = 0x04, // HEADERS, PUSH_PROMISE, CONTINUATION 表示header部分完了 PADDED = 0x08, // DATA, HEADERS, PUSH_PROMISE 表示payload后面有填充的数据 PRIORITY = 0x20, // HEADERS 表示有当前流有设置权重weight }; |
接着收到第4帧:
(4)HEADERS (stream id = 1; flag = 4; length = 107)
这个是请求响应头,是inde.html的,flag为4代表END_HEADERS,表示这个header只有一帧,如果flag为0就说明后面还有。然后Chrome会对收到的头部进行逐字节解析,按照上面提到的头部压缩的方式的逆过程。
先取出第一个字节,判断是什么类型的header,indexed或者非indexed,所谓indexed就是指查表能查到的,如第一个字节是0x82就是IndexedHeader。然后再把高位去掉,剩下0x02表示表的索引:
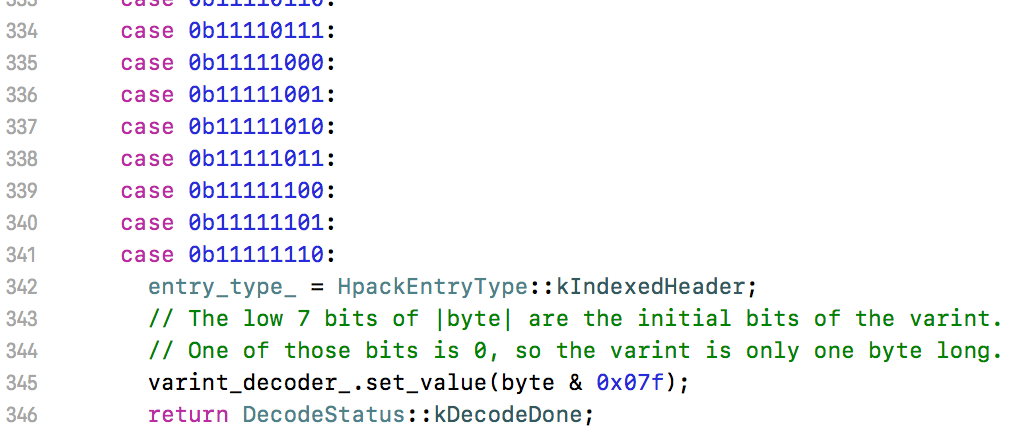
如果是IndexedHeader那么就会去动态表和静态表查:

否则的话就得去解析l字符串key/value和length,有可能使用了霍夫曼,也有可能没有,代码里面做了判断:
|
1 2 |
uint8_t h_and_prefix = db->DecodeUInt8(); bool huffman_encoded = (h_and_prefix & 0x80) == 0x80; |
Chrome也是维护了一个霍夫曼表:

解析完一对key/value头部字段之后,可能会把它压入动态表里面。接着继续解析下一个,直到length完了。
(5)DATA (stream id = 1; flag = 1; length = 385)
header帧之后就是index.html的数据帧了,这里flag为1表示END_STREAM,长度为385,因为数据比较小,一个帧就发送完了。
我们把收到的payload直接打印出来是这样的(我把gzip关了,不然打印出来是压缩过的内容):
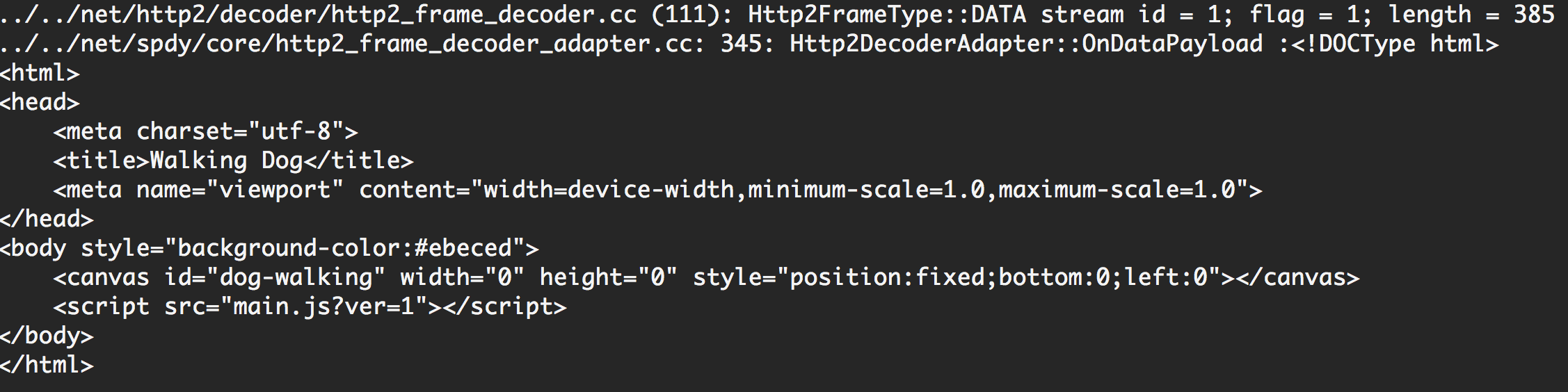
这个内容就是html文本,我们看到HTTP/2并没有对发送内容进行处理,只是对发送的形式进行了控制。经常说HTTP/2是二进制的,应该是说帧的头部是二进制,但是内容该怎么样还是怎么样。
(6)HEADERS(stream id = 3; flag = 4; length = 160)
接着又收到了一个头部帧,这个是main.css的响应头,stream id为3.
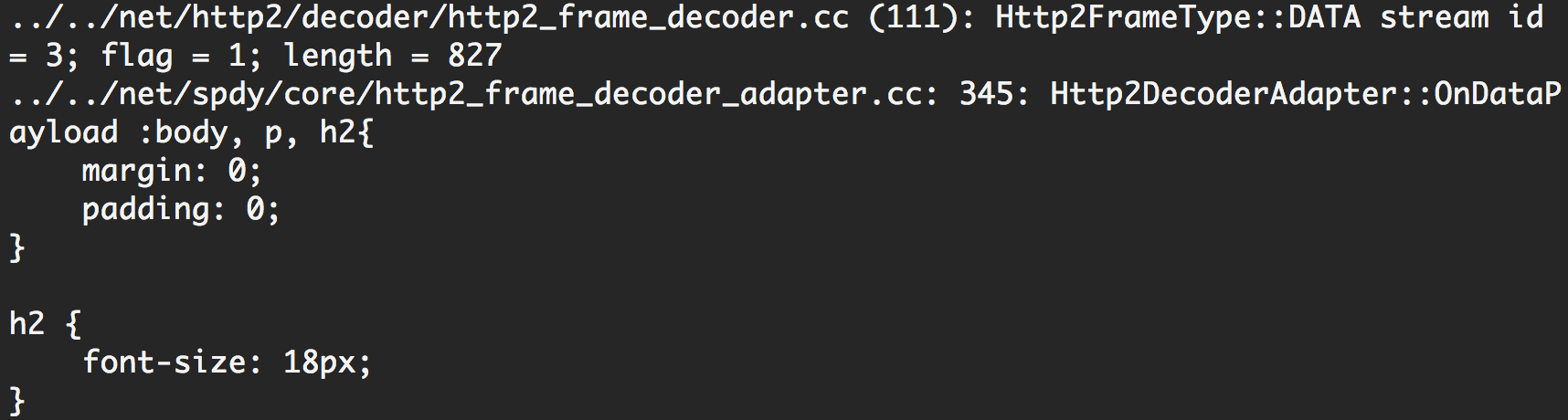
(7)DATA (stream id = 3; flag = 1; length = 827)
这个是main.css的数据帧:
(8)HEADERS (stream id = 5; flag = 4; length = 171)
这个是main.js的响应头
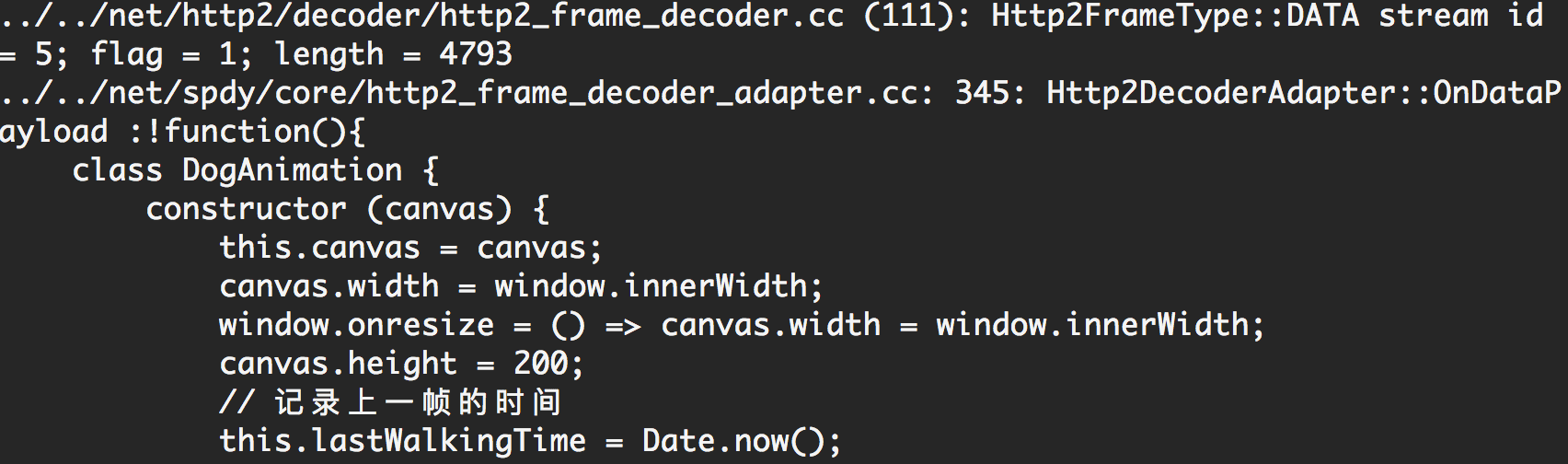
(9)DATA(DATA stream id = 5; flag = 1; length = 4793)
main.js的payload,如下图所示:
(10)HEADERS(HEADERS stream id = 7; flag = 4; length = 163)
这个是0.png的响应头
(11)DATA (stream id = 7; flag = 0; length = 8192)
0.png的payload:

注意这里的flag是0,不是1,说明后面还有数据帧。紧接着又收到了一帧:
(12)DATA (stream id = 7; flag = 1; length = 2843)
这个的stream id还是7,但是flag为1表示END_STREAM。说明0.png(11KB)被拆成了两帧发送。
我们发现stream的id都是奇数的,这是因为这些stream都是浏览器创建的,主动连接一方stream id使用奇数,而另一方触发创建的stream使用偶数,主要通过Server Push。
现在把Chrome发送的帧加进来,有了上面的基础再来理解Chrome的应该不难。
Chrome也会发送它的settings帧给对方,在初始化session的时候做的,代码是在net/spdy/chromium/spdy_session.cc的SendInitialData函数里面。我们把感兴趣的帧按顺序打印出来:
(1)SETTINGS
内容如下:
HEADER_TABLE_SIZE, value = 65536
MAX_CONCURRENT_STREAMS, value = 1000
INITIAL_WINDOW_SIZE, value = 6291456
Chrome做为接收方的时候流的最高并发数为1000.
(2)WINDOW_UPDATE
新增的window size大小为:
window_size_increment = 15663105
大概为15Mb。
接着,Chrome的IO线程取出一个request任务,取到的第一个是请求index.html,打印如下:
../../net/spdy/chromium/spdy_http_stream.cc (95) SpdyHttpStream::InitializeStream : request url = www.rrfed.com/html/walking-dog/index.html
它先创建一个HEADERS的帧
(3)HEADERS(index.html stream_id = 1; weight = 256; dependency = 0; flag = 1)
我们把帧头部的另外两个参数打印出来:weight权重和dependency依赖的流。权重为256,而依赖的流为0即没有。权重用来做来优先级的参考,值的范围为1 ~ 256,所以当前流拥有最高的优先级。依赖下文再提及。
在收到了html之后,Chrome解析到了main.css的link标签和main.js的script标签,于是又再重新初始化两个流,流都是通过发HEADERS的帧打开的。
(4)HEADERS(main.css stream_id = 3; weight = 256; dependency = 0; flag = 1 )
main.css也拥有最高的优先级
(6)HEADERS (main.js stream_id = 3; weight = 220; dependency = 3;flag = 1)
main.js的权重为220,这个script文件的权重要比html/css的小,并且它的依赖于id为3即main.css的流。
收到JS之后,解析JS,这个JS里面又触发加载了9张png图片,接着Chrome一口气初始化了9个流:
(7)~ (15)
0.png stream_id = 7, weight = 147, dependent_stream_id = 0, flags = 1
1.png stream_id = 9, weight = 147, dependent_stream_id = 7, flags = 1
2.png stream_id = 11, weight = 147, dependent_stream_id = 9, flags = 1
…
可以看到图片的权重又比script小,并且这些图片的流有一个依赖关系,后一个流依赖于前一个流。
依赖关系是在HEADER的payload里面指定的,如下图所示:

优先级依赖priority dependencies和窗口大小window size是HTTP/2进行多路复用控制的两个最主要的方法。这个依赖有什么用呢?如下文档的说明:
Inside the dependency tree, a dependent stream SHOULD only be allocated resources if either all of the streams that it depends on (the chain of parent streams up to 0x0) are closed or it is not possible to make progress on them.
意思是说一个依赖的子结点只有等到它所有的父结点都处理完了才能够给它分配资源进行处理。换句话说在这棵优先级依赖树里面,父结点比子结点拥有更高的处理优先级。文档里面只说明了优先级依赖树的一些特性,并没有说明应该如何实现,只是说不同的场景可以有不同的实现。Chrome又是怎么实现的呢?
它是用一个二维数组,第一维是priority,即用一个数组放优先级相同的stream id,当初始化一个流的时候就会把它放到相应priority的数组里面去。注意这里的priority是指spdy3的属性,从最高优化级的0到最低优化级7,和权重weight([1, 256])有一个转化关系,这里不讨论是怎么转换的,它们表达的意思是一样的。如下代码所示,把stream添加到相应优先级数组的后面:
|
1 |
id_priority_lists_[priority].push_back(std::make_pair(stream_id, priority)); |
但是这个二维数组并没有建立父子结点的关系,只是借助它可以知道当前流的父结点应该是哪个。计算当前流父结点的代码实现逻辑是在http2_priority_dependencies.cc这个文件里面,为了方便理解,我把它转成JS代码,它的思想是要找到比当前流的优先级离得最近且不低于当前优先级的一个流,代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
let stream_id = 1, // 当前流的id,从外面传进来 priority = 0, // 当前流的优先级,从外面传进来的 id_priority_lists_ = []; // 它是一个二维数组 id_priority_lists_[0] = []; // 这里先初始化一下 const kV3HighestPriority = 0; // 最高优先级为0 let dependent_stream_id = 0; // 父结点的stream id for (let i = priority; i >= kV3HighestPriority; i--) { let length = id_priority_lists_[i].length; if (length) { dependent_stream_id = id_priority_lists_[i][length - 1]; break; } } id_priority_lists_[priority].push(stream_id); |
这段代码应该比较好理解,在for循环里面从当前优先级一直往高优化级找,直到找到一个,如果没有,那么它的parent stream就是0,表示它是一个root结点。
另外,一旦流关闭了之后,就会把当前流从二维数组里面移除。所以在收到html之后,html的流就被删了,所以新建的CSS流就没有依赖的父结点了,但是紧接着新建的JS流它的优先级比CSS流低,所以这个JS流的父结点就是CSS流。
我们看到Chrome并没有实际地存放这么一棵树,只是借助这么一个二维数组找到当前stream的父结点,设置在HEADER帧的dependency,然后传给服务端,告诉服务端这些流的优先级依赖关系。
服务端又是怎么利用这些优先级依赖关系的呢?我们以nginx为例,通过nginx的源码,可以大致知道nginx是怎么操作的,nginx是有真正建立一棵依赖树的,每一个流都会对应一个node结点。每个结点都会记录它的父结点parent,它的子结点集children,以及当前结点的weight和rank,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
struct ngx_http_v2_node_s { ngx_uint_t id; ngx_http_v2_node_t *index; ngx_http_v2_node_t *parent; ngx_queue_t queue; ngx_queue_t children; ngx_queue_t reuse; ngx_uint_t rank; ngx_uint_t weight; double rel_weight; ngx_http_v2_stream_t *stream; }; |
在实际计算中是用的rel_weight相对权重和rank排名,这个相对权重和排名是利用weight和dependency计算的:
|
1 2 3 4 5 6 7 8 9 10 11 |
// 如果当前结点没有父结点,那么它的排名就为第一 if (parent == null) { node->rank = 1; node->rel_weight = (1.0 / 256) * node->weight; } // 否则的话,它的排名就是父结点的排名加1 // 而它的相对权重就是父结点的 weight/256 else { node->rank = parent->rank + 1; node->rel_weight = (parent->rel_weight / 256) * node->weight; } |
可以看到子结点的相对权重rel_weight等于父结点的weight/256倍,注意weight <= 256,而子结点的排名rank是排在父结点的后一位。当前结点的weight和父结点是哪个是浏览器通过HEADERS帧告诉的,也就是说nginx利用这两个参数把当前流节点插入这个依赖树里面,通过这棵树计算出当前结点的排名和相对权重。
知道这两个有什么用呢?
当流的并发数超过最高并发数max_concurrent_streams时,或者缓存空间buffer用完了,这个时候要把当前流放到waiting_queue里面,这个队列有一个顺序,越靠前的元素就能越快处理,优先级越高就越靠前。当把一个需要waiting的stream插入到这个队列的时候就需要用到优先级排名决定要插到哪个位置,如下ngx_http_v2_waiting_queue函数的实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// stream表示要插入的流 stream->waiting = 1; // 从waiting列队的最后一个元素开始,依次往前遍历,直到完了 for (q = ngx_queue_last(&h2c->waiting); q != ngx_queue_sentinel(&h2c->waiting); q = ngx_queue_prev(q)) { // 取出当前元素的数据 s = ngx_queue_data(q, ngx_http_v2_stream_t, queue); // 这段代码的核心在于这个判断 // 如果要插入的流的排名比当前元素的排名要靠后, // 或者排名相等但是相对权重比它小,就插到它后面。 if (s->node->rank < stream->node->rank || (s->node->rank == stream->node->rank && s->node->rel_weight >= stream->node->rel_weight)) { break; } } // 这里执行插入,如果stream的优先级比队列的任何一个元素 // 都要高的话,就插到队首去了 ngx_queue_insert_after(q, &stream->queue); |
把当前stream插到比它优先级稍高的一个元素的后面去,利用了rank和rel_weight. rank是由dependency决定,而rel_weight主要是由weight决定。
我们发现nginx在发送帧队列的时候也是用的类似的判断来决定帧的发送顺序,如下ngx_http_v2_queue_frame函数代码:
|
1 2 3 4 5 6 7 |
if ((*out)->stream->node->rank < frame->stream->node->rank || ((*out)->stream->node->rank == frame->stream->node->rank && (*out)->stream->node->rel_weight >= frame->stream->node->rel_weight)) { break; } |
HTTP/2的多路复用就介绍到这里,上面说的流都是由浏览器主动打开的,而HTTP/2的Server Push的流是由服务触发打开的。
3. Server Push
当我们使用HTTP/1.1的时候,Chrome最多同时加载6个:

而当我们使用HTTP/2的时候,就没有这个限制,有的是流的最大并发数,如上面提到的100个,如下图所示:
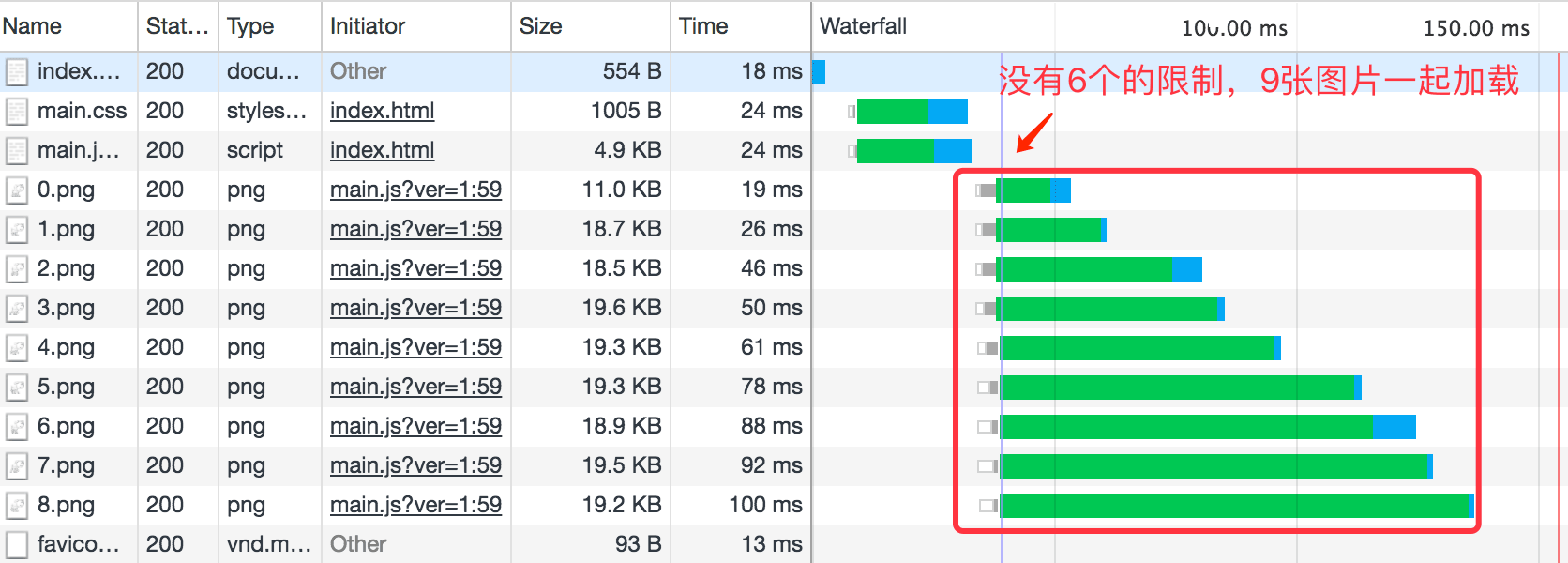
我们观察到图片的加载完成时间是从上往下的,这个就应该是上面提到的优先级依赖影响的,后面的图片会依赖于前面的图片,所以前面的图片优先级会更高一点,优先传递。时间线里面绿色的是表示Waiting TTFB(Time To First Byte)的时间,即发出请求之后到收到第一个字节所需要的时间,蓝色是内容下载时间。这里可以看到等待时间TTFB依次增长。
虽然使用了HTTP/2没有了6个的限制,但是我们发现css/js需要在html解析了之后才能触发加载,而图片是通过JS的new Image触发加载,所以它们需要等到JS下载完并解析好了才能开始加载。
所以Server Push就是为了解决这个加载延迟问题,提前把网页需要的资源Push给浏览器。Nginx 1.13.9版本开始支持,是在最近(2018/2)才有的。通过编译一个新版本的nginx就能体验Server Push的功能,给nginx.conf添加以下配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
location = /html/walking-dog/index.html { http2_push /html/walking-dog/main.js?ver=1; http2_push /html/walking-dog/main.css; http2_push /html/walking-dog/dog/0.png; http2_push /html/walking-dog/dog/1.png; http2_push /html/walking-dog/dog/2.png; http2_push /html/walking-dog/dog/3.png; http2_push /html/walking-dog/dog/4.png; http2_push /html/walking-dog/dog/5.png; http2_push /html/walking-dog/dog/6.png; http2_push /html/walking-dog/dog/7.png; http2_push /html/walking-dog/dog/8.png; } |
指定需要Push的资源,然后观察加载的时间线:

我们发现加载时间有了一个质的改变,基本上在100ms左右就加载完了。所以Sever Push用得好的话作用还是挺大的。
Server Push的流是通过Push Promise类型的帧打开的,Promise的帧格式如下图所示:

它其实就是一个请求的HEADER帧,但是它和HEADER又不太一样,没有weight/dependency那些东西。
按照上面的方式,观察一下加上Push Promise之后,帧传递的过程是怎么样的。
浏览器在stream_id = 1的流里面请求加载index.html,这个时候服务并没有立刻响应头部和数据,而是先连续返回了11个Push Promise的帧,stream的id分别为2、4、6等,然后浏览器立刻创建了相应的stream,收到了2的promise之后就创建2的stream,收到4的之后就创建4的。这个时候流创建好了就开始加载,不用等到解析到html或者js之后才开始。
在这个过程中,Chrome会先解析promised stream id,如下图所示:

然后再去解析Hpack的头部,再用这个头部去创建流。Server Push我们就不再深入讨论了,读者可以打开这个网址感受一下。
综上,我们主要讨论了HTTP/2的三大特性:
(1)头部压缩,通过规定头部字段的静态表格和实际传输过程中动态创建的表格,减少多个相似请求里面大量冗余的HTTP头部字段,并且引入了霍夫曼编码减少字符串常量的长度。
(2)多路复用,只使用一个TCP连接传输多个资源,减少TCP连接数,为了能够让高优先级的资源如CSS等更先处理,引入了优先级依赖的方法。由于并发数很高,同时传递的资源很多,如果网速很快的时候,可能会导致缓存空间溢出,所以又引入了流控制,双方通过window size控制对方的发送。
(3)Server Push,解决传统HTTP传输中资源加载触发延迟的问题,浏览器在创建第一个流的时候,服务告诉浏览器哪些资源可以先加载了,浏览器提前进行加载而不用等到解析到的时候再加载。
国内使用HTTP/2的还没怎么见到,淘宝之前是有开启HTTP/2的,不知道为什么现在又下掉了, 国外使用HTTP/2的网站还是很多的,像谷歌搜索、CSS-Tricks、Twitter、Facebook等都使用了HTTP/2。如果你有自己的网站的话,可以尝试一下。
相关阅读:
目录: 基础技术
Tags: chrome源码
向ScottDax进行回复 取消回复