本篇解读基于Chromium 66。HTTP协议起很大作用的是http头,它主要是由一个个键值对组成的,例如Content-Type: text/html表示发送的数据是html格式,而Content-Encoding: gzip指定了内容是使用gzip压缩的,Transfer-Encoding: chunked又表示它使用分块传输编码,等等。
从Chrome发的请求复制一个原始的请求报文头如下所示,如访问http://payment-admin.com/list将会发送以下请求报文:
|
1 |
"GET /list HTTP/1.1\r\nHost: payment-admin.com\r\nConnection: keep-alive\r\nCache-Control: max-age=0\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3345.0 Safari/537.36\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate\r\nAccept-Language: en-US,en;q=0.9\r\nIf-None-Match: W/\"68104920-260-\"2018-02-13T14:16:35.000Z\"\"\r\nIf-Modified-Since: Tue, 13 Feb 2018 14:16:35 GMT\r\n\r\n" |
这个是按照http报文格式拼接的字符串,如下图所示:

对于每个请求,Chrome都会自动设置UA字段:
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3345.0 Safari/537.36
Chrome的UA字段是这么拼的:
Mozilla/5.0 ([os_info]) AppleWebKit/[webkit_major_version].[webkit_minor_version] (KHTML, like Gecko) [chrome_version] Safari/[webkit_major_version].[webkit_minor_version]
如下源码所示:
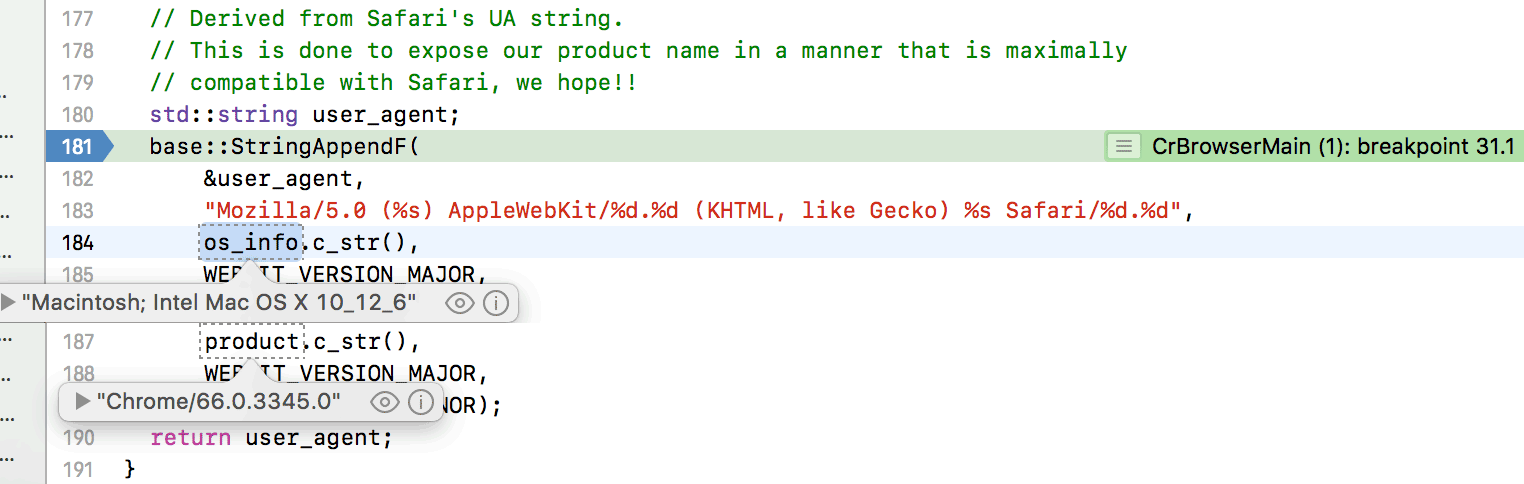
并且我们看到源码的注释还说明了为什么UA要带上Safari——为了以最大限度地与Safari兼容的方式展示产品名称。
当前请求收到了以下响应报文头:
“HTTP/1.1 200 OK\0Server: nginx/1.8.0\0Date: Fri, 16 Feb 2018 03:31:51 GMT\0Content-Type: text/html; charset=UTF-8\0Transfer-Encoding: chunked\0Connection: keep-alive\0last-modified: Tue, 13 Feb 2018 14:16:35 GMT\0etag: W/\”68104920-260-\”2018-02-13T14:16:35.000Z\”\”\0cache-control: max-age=10\0Expires: Fri, 16 Feb 2018 03:32:01 GMT\0Content-Encoding: gzip\0\0″
这个请求报文头和响应报文头有个小区别,它的字段间的分隔符是\0,而不是上面的\r\n了。
对于请求报文头字段,我们重点讨论以下两个问题:
(1)缓存是以什么做为键值的,即如何区分两个不同的资源,缓存浏览器是如何组织管理的?
(2)gzip是如何压缩和解压的,为什么通过gzip压缩体积经常能小一半以上?
对于缓存,首先怎么设定资源的缓存时间呢?如果使用nginx,可以这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
server { listen 80; server_name www.rrfed.com; # .json不要缓存,时间为0 location ~* \.sw.json$ { expires 0; } # 如果是图片的话缓存30天 location ~* \.(jpg|jpeg|png|gif|webp)$ { expires 30d; } # css/js缓存7天 location ~* \.(css|js)$ { expires 7d; } } |
上述代码根据对不同的文件名后缀区分设置缓存时间,如图片缓存30天,js/css缓存7天。
如果使用Node.js等在请求里面单独添加的,可以直接添加Cache-Control的头:
|
1 2 |
// 设置30天=2592000s缓存 response.setHeader("Cache-Control", "max-age=2592000"); |
这样浏览器就能收到缓存的http头了:
![]()
那么浏览器是如何区分不同的资源进行缓存的?你可能已经猜到了,根据url,如下图所示:
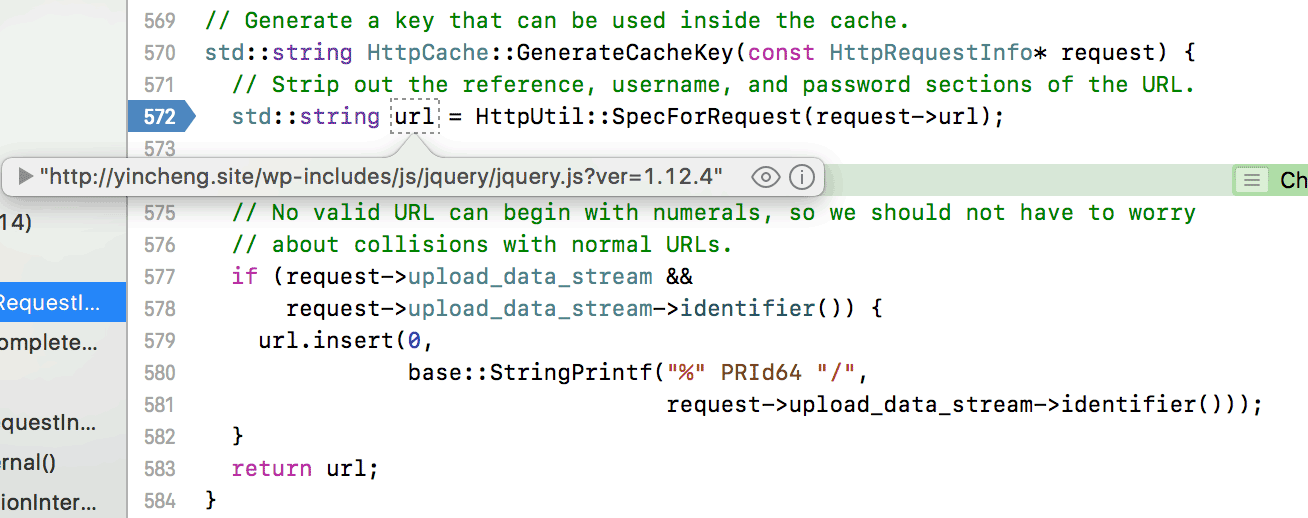
Chrome使用一个生成Cache Key的函数,这个函数是使用请求的url作为缓存的key值。
如果这样的话,POST等请求是不是也可以被缓存?实际上并不是的,因为它上面还有一个判断,如下图所示:

这个ShouldPassThrough会对请求方式进行判断:
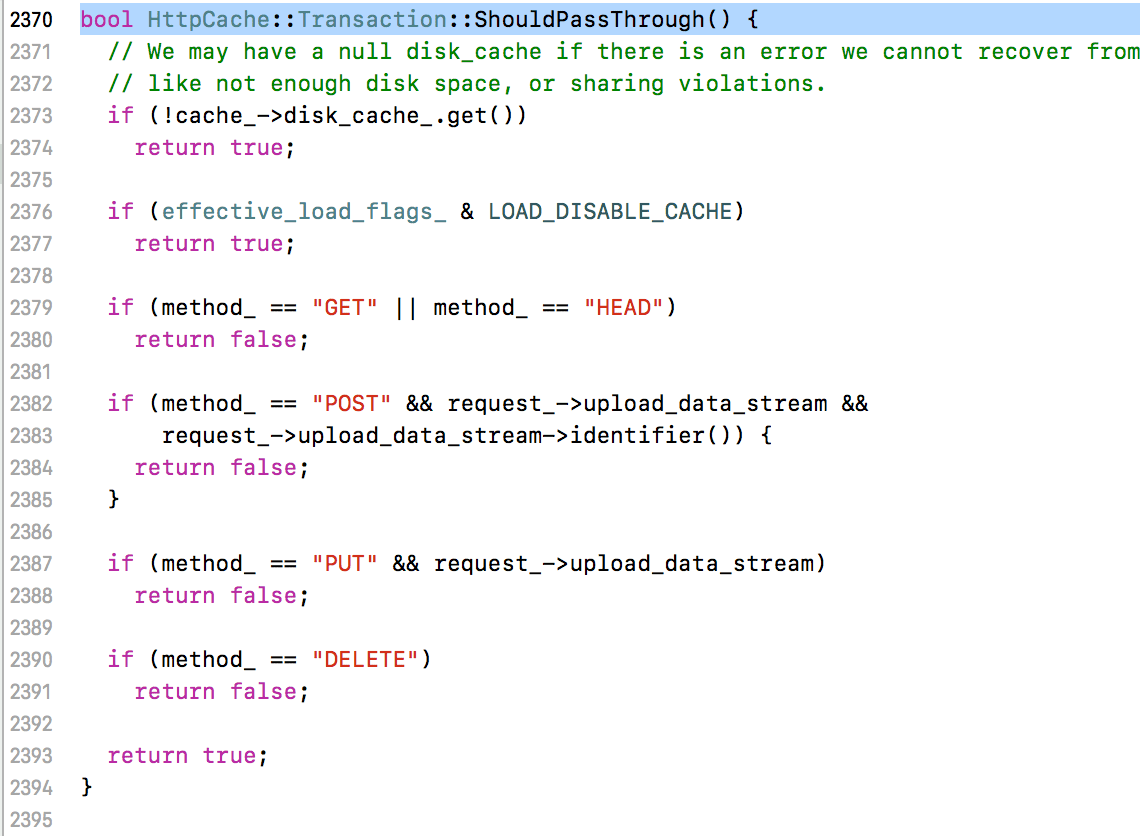
如果是普通的POST/PUT,是返回true的,也就是说,这种请求是直接返回true的,是需要pass的,不用取缓存。而对于DELETE和HEAD,在另外一个地方做的判断:

如果mode为NONE的话,就会去发请求了。也就是说除了GET之外,Chrome基本上不会对其它请求方式进行缓存。
请求完之后会对cache进行存储,通过打断点检查可以发现是放在了这个路径下
~/Library/Caches/Chromium/Default/Cache/
如下图所示:

这个目录下的缓存文件是以key值(即url)的SHA1哈希值做为文件名:

查看这个Cache目录,可以发现文件名是以哈希值加上一个0或1的后缀组成,0/1是file index(具体不深入讨论),如下图所示:

缓存文件不是把文件内容写到硬盘,而是把Chrome封装的Entry实例内存内容序列化写到硬盘,它是变量在内存的表示。如果用文本编辑器打开缓存文件是这样的:
![]()
可直接读取成相应的变量。
同时会把这个Entry放在entries_set_内存变量里面,它是一个unordered_map,即普通的哈希Map,key值就是url的sha1值,value值是一个MetaData,它保存了文件大小等几个信息,EntrySet的数据结构如下代码所示:
|
1 |
using EntrySet = std::unordered_map<uint64_t, EntryMetadata>; |
这个entries_set_最主要的作用还是记录缓存的key值,所以它的命名是叫set而不是map。这个变量会保存它的序列化格式到硬盘,叫做索引文件index:
~/Library/Caches/Chromium/Default/Cache/index-dir/the-real-index
Chrome在启动的时候就会去加载这个文件到entries_set_里面,加载资源的时候就会先这个哈希Map里面找:

如果找得到就直接去加载硬盘文件,不去发请求了。
数据取出来之后,就会对缓存是否过期进行验证:

验证是否过期需要先计算当前的缓存的有效期,如下源码的注释:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// From RFC 2616 section 13.2.4: // // The max-age directive takes priority over Expires, so if max-age is present // in a response, the calculation is simply: // // freshness_lifetime = max_age_value // // Otherwise, if Expires is present in the response, the calculation is: // // freshness_lifetime = expires_value - date_value // // Note that neither of these calculations is vulnerable to clock skew, since // all of the information comes from the origin server. // // Also, if the response does have a Last-Modified time, the heuristic // expiration value SHOULD be no more than some fraction of the interval since // that time. A typical setting of this fraction might be 10%: // // freshness_lifetime = (date_value - last_modified_value) * 0.10 // |
结合代码实现逻辑,这个步骤是这样的:
(1)如果给了max-age,那么有效期就是max-age指定的时间:
cache-control: max-age=10
cache-control: no-cachecache-control: no-store
(2)如果没有给max-age,但是给了expires,那么就使用expires指定的时间减去当前时间得到有效期:
Expires: Wed, 21 Feb 2018 07:28:00 GMT
这个日期是http-date格式,使用GMT时间。
(3)如果max-age和expires都没有,并且没有指定must-revalidate,就使用当前时间减掉last modified time乘以一个调整系数0.1做为有效期:
last-modified: Tue, 13 Feb 2018 08:16:27 GMT
cache-control: max-age=10, must-revalidatecache-control: must-revalidate
那么就不能直接使用缓存,要发个请求,如果服务返回304那么再使用缓存。
有了有效期之后再和当前的年龄进行比较,如果有效期比年龄还大则认为有效,否则无效。而这个年龄是用当前时间减掉资源响应时间,再加上一个调整时间得到:
|
1 2 |
// resident_time = now - response_time; // current_age = corrected_initial_age + resident_time; |
因为考虑到请求还需要花费时间等因素,current_age需要做一个修正。
关于缓存就说到这里,接下来讨论gzip压缩。
gzip压缩经常能把一个文件的体积压到一半以下,如jquery-3.3.1.min.js有85kb,通过gzip压缩就剩下35kb:

减小了58%的体积。所以gzip是怎么压的呢?这个是我一直很好奇的问题。
在linux/mac上经常可以看到.tar.gz后缀的文件名,.tar表示打成了一个tar包,而.gz表示把tar包用gzip压缩了一下,可以用以下命令压缩和解压:
|
1 2 3 4 5 |
# 把html目录打包成一个压缩文件 tar -zcvf html.tar.gz html/ # 解压到当前目录 tar -zxvf html.tar.gz |
gzip已经被标准化成RFC1952,nginx开启gzip可通过添加以下配置:
|
1 2 3 4 5 6 7 8 |
server { gzip on; gzip_min_length 1k; gzip_buffers 4 16k; # gzip_http_version 1.1; gzip_comp_level 2; gzip_types text/plain application/javascript application/x-javascript text/javascript text/xml text/css application/x-httpd-php image/jpeg image/gif image/png; } |
Chrome是使用第三方的zlib库做为压缩和解压的库,其解压使用的库文件是third_party/zlib/contrib/optimizations/inflate.c,这个代码看起来比较晦涩,具体过程可以参考这个deflate的说明和这一个,gzip依赖于deflate,deflate是结合了霍夫曼编码和LZ77压缩。以压缩以下文本做为说明:
“In the beginning God created the heaven and the earth. And the earth was without form, and void.”
先对它进行LZ77压缩变成:
In the beginning God created<25, 5>heaven an<14, 6>earth. A<23, 12> was without form,<55, 5>void.
其中<25, 5>代表<distance, length>,表示字符串” the “,25是距离distance,在当前位置往前25个字节,再取长度length = 5,就是最开始那个” the “。同理,后面的<14, 6>表示”d the “。
一个字节有8位可以表示的最大数字为255,假设用一个字节表示distance,一个字节表示length,那么上述文本由没有压缩的96B变成76B,其压缩率已达到80%,如果文本越长,那么重复的概率越大,压缩率越高。标准建议最大的块长度为32kb,即超过32kb后重复字符重新开始算。
但是有个问题是:如何区分正常的内容和表示<distance, length>的长度对?标准是这么解决的,值为0 ~ 255的为正常内容,而256表示块结束,257 ~ 285表示长度对。
为了表示数字285最小需要9个位,也就是说可以每9位 9位地读取值(同理以9位为单位进行压缩),这样可以解决问题,但是会大量地浪费空间,因为9位最大能表示511.所以引入了可变长度编码霍夫曼编码,数据的存储不再是固定长度的(如每一个字节表示一个内容),而是可变的,最短可能是1位表示一个字符,最长可能是9位。
但是这样可能会区分不了,如A、B、C 3个字符分别表示为:
A:0
B:1
C:01
那么当遇到01的时候就不知道是C还是AB了。
所以霍夫曼编码就是为了解决保证前缀不冲突的问题,如下图所示:
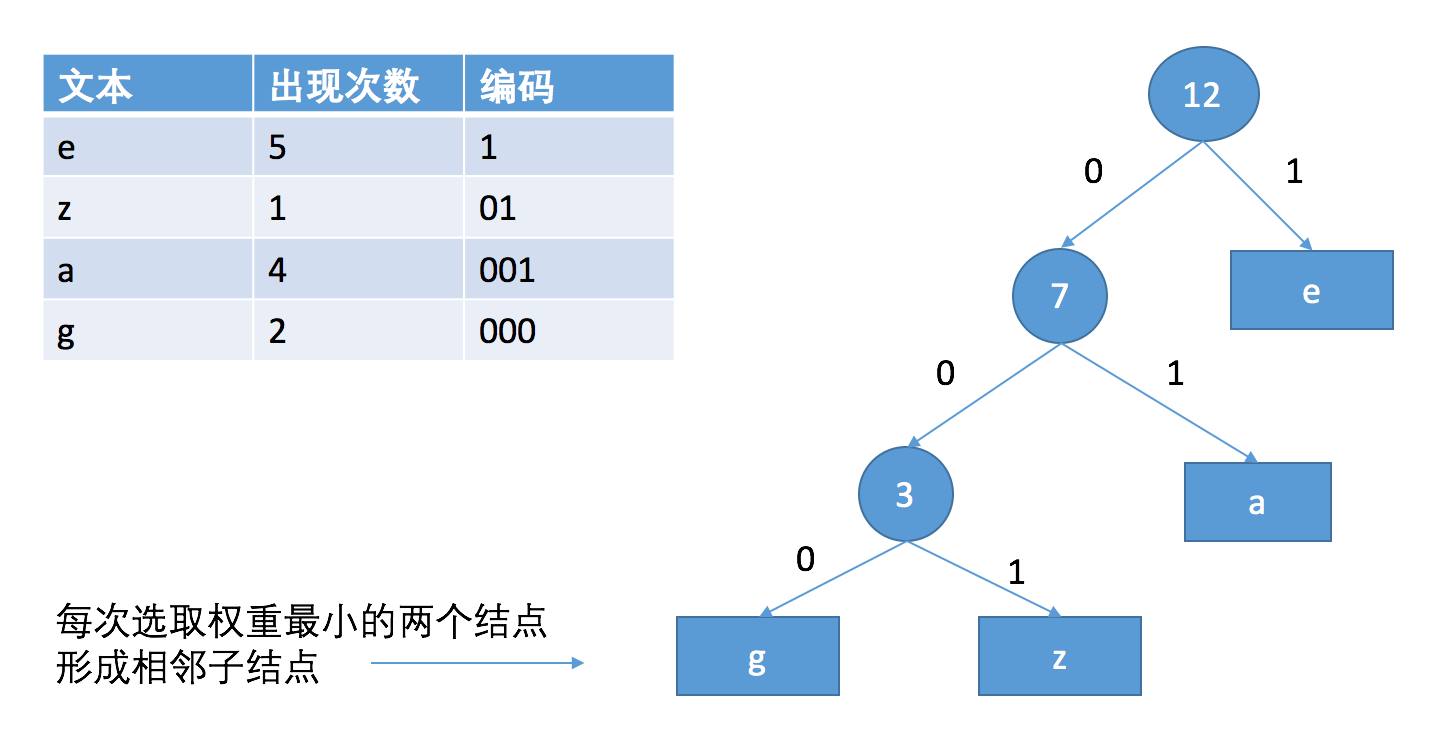
先统计每个字符出现的次数,然后每次选取两个次数最小的字符形成左右子结点,它们的和做为父结点做为一个新的结点,直到所有结点形成一棵树,左子树代表0,右子树代表1,从根结点到叶子结点的路径就是当前字符的编码,如z的编码就是001,而e是1,这样高频率出现的符号的编码会比较短,就达到了压缩的目的。同时需要有一个表记录编码的对应关系,在解压的时候进行查找。(标准还对这个算法进行了优化)。
刚才提到长度对的范围是257 ~ 285共29个,这样是不够用的,因为一个块最大有32kb(取决于压缩率),重复字符串如果最长只能有29个或者只能往前找29个,那么不能进行充分地压缩,因此标准还在后面添加了额外的位进行加大,如下所示:
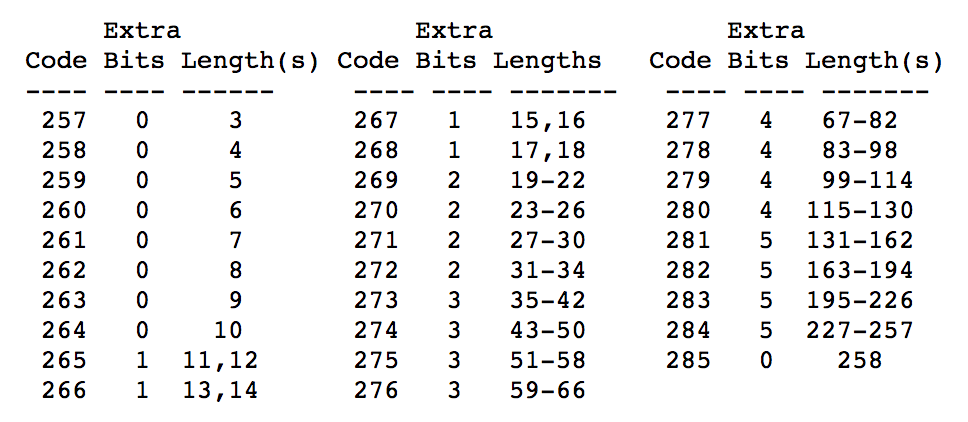
例如如果length是266,那么后面还要再读1位,如果这1位是0,那么length就为13,如果这1位是1,那么length就是14,依次类推。length后面紧接着就是distance,distance也会类似地处理。我们看到length最大为258,而distance最大为32kb。
gzip的特点是压缩比较费时,但是解压比较容易。压缩需要统计字符,查找重复字符串,而解压只需要查下可变长度编码表,然后读取比较value大小看是否为内容还是长度对再进行输出。gzip压缩率好坏取决于内容的重复度,重复率越高,则压缩率越高。
本篇对HTTP的解读就到这里,主要讲述了三个内容:HTTP报文头、HTTP缓存、Gzip压缩。看完了本文应该会了解HTTP请求头和响应头分别是长什么样的,Chrome的UA是怎么拼出来的,HTTP缓存浏览器是怎么组织管理的、缓存时间又是怎么计算的,Gzip压缩的过程是怎么样的、为什么Gzip的压缩效果普遍较好等问题。对于HTTP其它感兴趣的内容我们下回再分解。
目录: 基础技术
Tags: chrome源码
发表评论