HTTP大家都不陌生,但是HTTP的许多细节就并不是很多人都知道了,本文将讨论一些容易被忽略但又比较重要的点。
首先,怎么用原生JS写一个GET请求呢?如下代码,只需3行:
|
1 2 3 |
let xhr = new XMLHttpRequest(); xhr.open("GET", "/list"); xhr.send(); |
xhr.open第一个参数是请求方法,第二个参数是请求url,然后把它send出去就行了。
如果需要加上请求参数,如果用jQuery的ajax,那么是这么写的:
|
1 2 3 4 5 6 |
$.ajax({ url: "/list", data: { page: 5 } }); |
如果是用原生的话就得拼在请求url上面,即open的第二个参数:

并且参数需要转义,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function ajax (url, data) { let args = []; for (let key in data) { // 参数需要转义 args.push(`${encodeURIComponent(key)} = ${encodeURIComponent(data[key])}`); } let search = args.join("&"); // 判断当前url是否已有参数 url += ~url.indexOf("?") ? `&${search}` : `?${search}`; let xhr = new XMLHttpRequest(); xhr.open("GET", url); xhr.send(); } |
那为什么用jQuery就不用呢?因为jQuery帮我们做了,jQuery的ajax支持一个叫processData的参数,默认为true:
|
1 2 3 4 5 6 7 |
$.ajax({ url: "/list", data: { page: 5 }, processData: true }); |
这个参数的作用是用来处理传进来的data的,如下jQuery的源码:

如果传了data,并且processData为true,并且data不是一个string了,就会调param处理data。然后我们来看下这个param函数是怎么实现的:

可以看到,它也是跟我自己实现的ajax类似,把key和value转义用”=”拼接,然后push到一个数组,最后再join地一下。不一样的地方是它的判断逻辑比我的复杂,它会再调一个buildParams的函数去处理key/value,因为value可能是一个数组,也可能是一个Object。如果value是一个Object,那么直接encode一下就会变成”[object Object]”的转义了:

所以buildParams在处理每个key/value时,会先判断当前value是否是一个数组或者是Object,如下图所示:
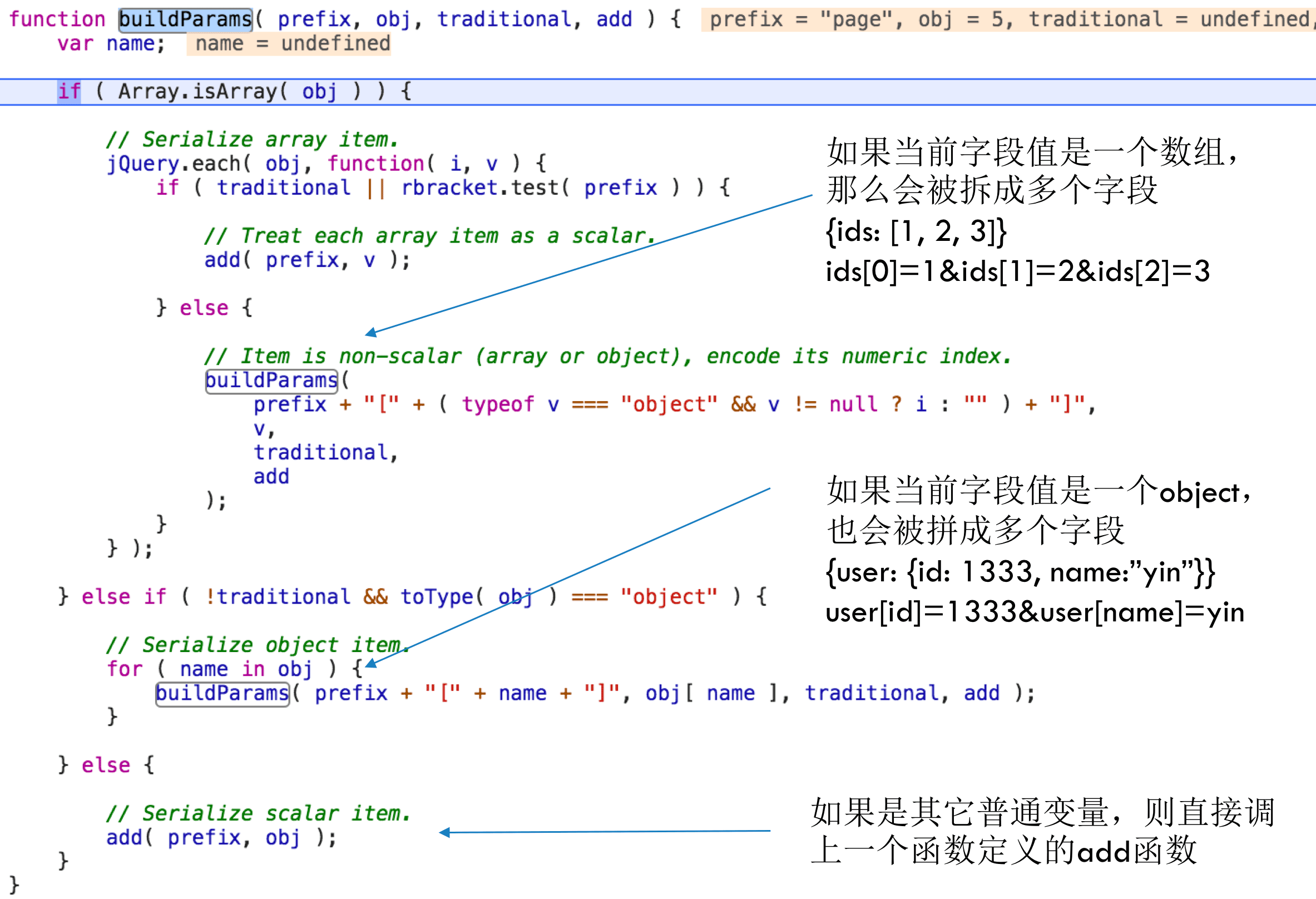
如果它是一个数组的话,这个数组的每一个元素都会变成单独的一个请求字段,它的key是父级的key拼上数组的索引得到,如{ids: [1, 2, 3]}就会被拼成:ids[0]=1、ids[1] = 2、ids[2] = 3,如果是一个Object的话key的后缀就是子Object的key,如{user: {id: 1333, name: “yin”}}会被拼成:user[id]=1333、user[name]=yin,否则就认为它是一个简单的类型,就直接调一下param函数定义的add,把它push到s那个数组。这里用到了递归调用,会不断地拼key值,直到value是一个普通变量了,就到了最后面的else逻辑。
也就是说,以下代码:
|
1 2 3 4 5 6 7 8 9 |
$.ajax({ url: "/list", data: { user: { name: "yin", age: 18 } }, }); |
将会被拼成的url为:
/list?user[name]=yin&user[age]=18
注意上面的中括号还没有转义。而如果是一个数组的话:
|
1 2 3 4 5 6 |
$.ajax({ url: "/list", data: { ids: [1, 2, 3] }, }); |
拼成的请求url为:
/list?ids[0]=1&ids[1]=2&ids[2]=3
如果后端用的Java的Spring MVC框架的话,是理解这种格式的,框架收到这样的参数后会生成一个Array,传递给业务代码,业务代码是不用关心怎么处理这种参数的。其它的框架应该也类似。
怎么用原生JS写一个POST请求呢?如下图所示:

POST请求的参数就不是放在url了,而是放在send里面,即请求体。你可能会问:难道就不能放url么?我就要放url。如果你够任性,那么可以,前提是后端所使用的http框架能够在url里面取数据,因为它一定会收到url,也一定会收到请求体,所以取决于它要怎么处理,按照http标准,如果请求方法是POST,那么应该是得去请求体拿的,就不会在url的search上取了,当然它可以改一下,改成两个都可以拿。
然后我们会发现请求的mime类型是text/plain:

并且查看请求参数的时候,并不是平时所看到能够按照字段一行行地展示:

这是为什么呢?这是因为我们没有设置它的Content-Type,如下代码:
|
1 2 3 4 5 |
let xhr = new XMLHttpRequest(); xhr.open("POST", "/add"); xhr.setRequestHeader("Content-type", "application/x-www-form-urlencoded"); xhr.send("id=5&name=yin"); |
如果设置Content-Type为x-www-form-urlencoded的话,那么在检查的话,Chrome也会按字段分行展示了:

这个也是jQuery默认的Content-Type:
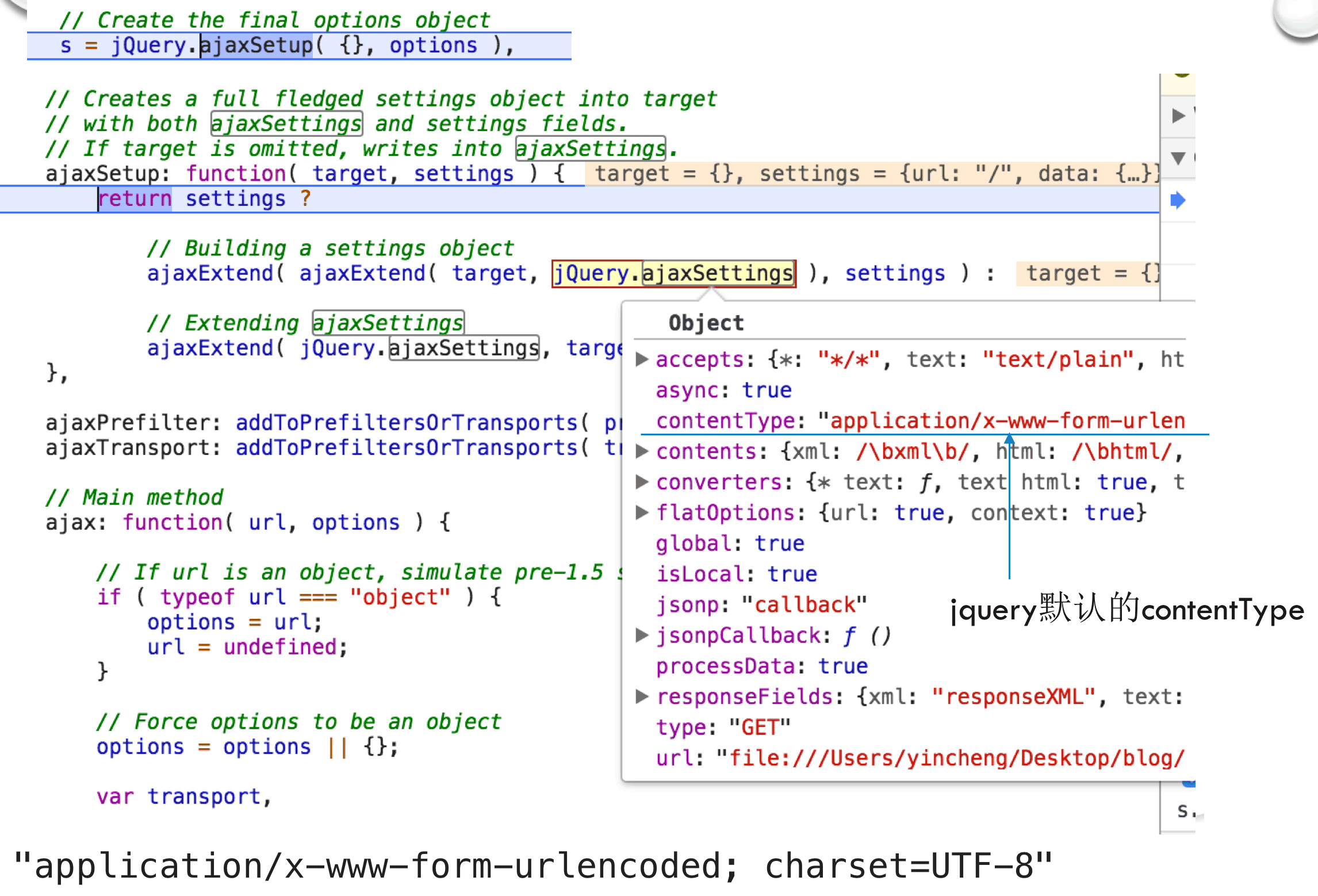
它是一种最常用的一种请求编码方式,支持GET/POST等方法,特点是:所有的数据变成键值对的形式key1=value1&key2=value2的形式,并且特殊字符需要转义成utf-8编号,如空格会变成%20:

由于中文在utf-8需要占用3个字节,所以它有3个%符号。
我们刚刚是xhr.send一个字符串,如果send一个Object会怎么样呢?如下代码所示:
|
1 2 3 |
var xhr = new XMLHttpRequest(); xhr.open("POST", "/add"); xhr.send({id:5, name: "yin"}); |
检查控制台的时候是这样的:

也就是说,实际上是调了Object的toString方法。所以可以看到,在send的数据需要转成字符串。
除了字符串之外,send还支持FormData/Blob等格式,如:
|
1 2 |
let form = $("form")[0]; xhr.send(new FormData(form)); |
但最后都是被转成字符串发送。
我们再看下其它的请求格式,如Github的REST API是使用json的格式发请求:

这个时候要求格式要变成json,就需要指定Content-Type为application/json,然后send的数据要stringify一下:
|
1 2 3 4 5 |
let xhr = new XMLHttpRequest(); xhr.open("POST", "/add"); xhr.setRequestHeader("Content-type", "application/json"); let data = {id:5, name: "yin"}; xhr.send(JSON.stringify(data)); |
如果是用jQuery的话,那么可以这样:
|
1 2 3 4 5 |
$.ajax({ processData: false, data: JSON.stringify(data), contentType: "application/json" }); |
这个时候processData为false,告诉jQuery不要处理数据了——即拼成key1=value1&key2=value2的形式,直接把传给它的数据send就好了。
我们可以比较json和urlencoded这两种形式的优缺点,json的缺点是parse解析的工作量要明显高于split(“&”)的工作量,但是json的优点又在于表达复杂结构的时候比较简洁,如二维数组(m * n)在urlencoded需要拆成m * n个字段,而json就不用了。所以相对来说,如果请求数据结构比较简单应该是使用常用的urlencoded比较有利,而比较复杂时使用json比较有利。通常来说比较常用的还是urlencoded.
还有第3种常见的编码是multipart/form-data,这种也可以用来发请求,如下代码所示:
|
1 2 3 4 5 6 7 |
let formData = new FormData(); formData.append("id", 5); // 数字5会被立即转换成字符串 "5" formData.append("name", "#yin"); // formData.append("file", input.files[0]); let xhr = new XMLHttpRequest(); xhr.open("POST", "/add"); xhr.send(formData); |
它通常用于上传文件,上传文件必须要使用这种格式。上面代码发送的内容如下图所示:

每个字段之间用一个随机字符串隔开,保证发送的内容不会出现这个字符串,这样发送的内容就不需要进行转义了,因为如果文件很大的话,转义需要花费相当的时间,体积也可能会成倍地增长。
然后再讨论一个问题,我们知道在浏览器地址栏输入一个网址请求数据,这个时候是用的GET请求,而我们在代码里面用ajax发的GET请求也是GET,浏览器访问网址的GET和ajax的GET有什么区别吗?
为了能够观察到浏览器自已发出去的GET,需要用一个抓包工具看一下这个GET是怎么样的,如下图所示:
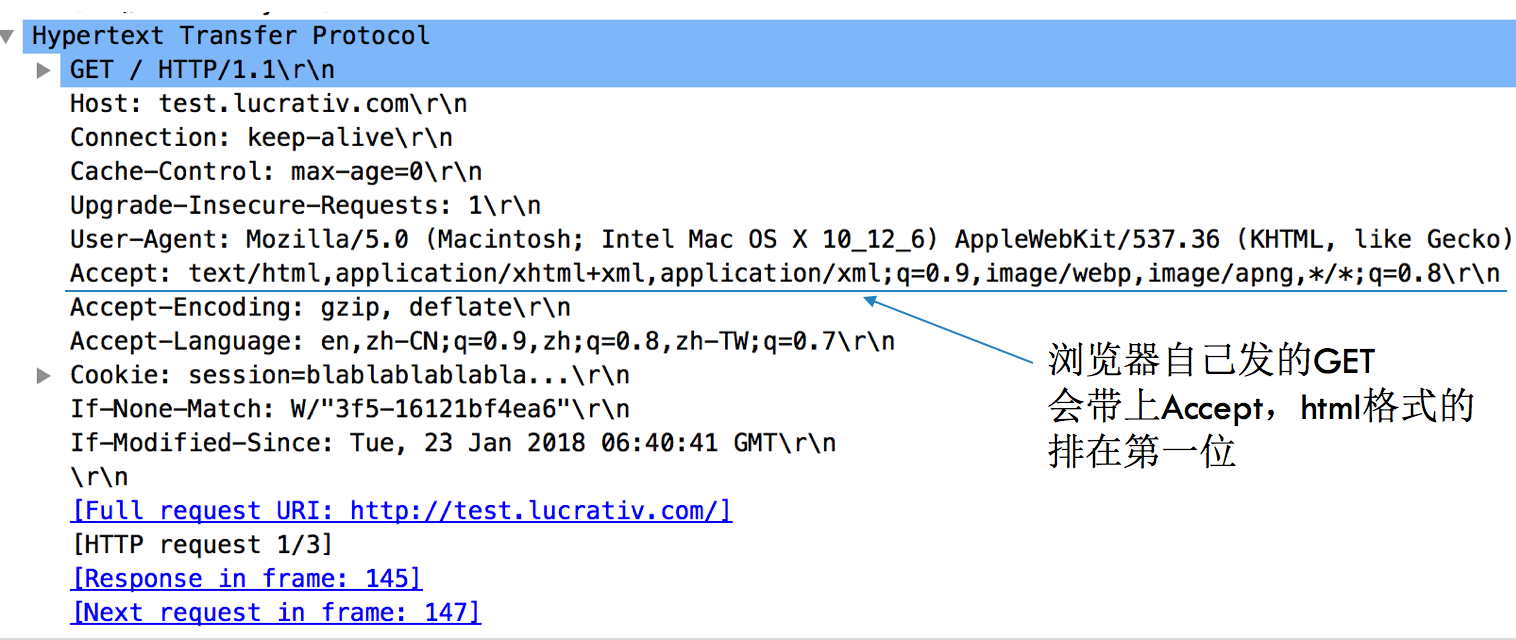
浏览器自己发的GET有一个明显的特点,它会设置http请求头的Accept字段,并且把text/html排在第一位,即它最希望收到的是html格式。而动态的ajax抓包显示是这样的:
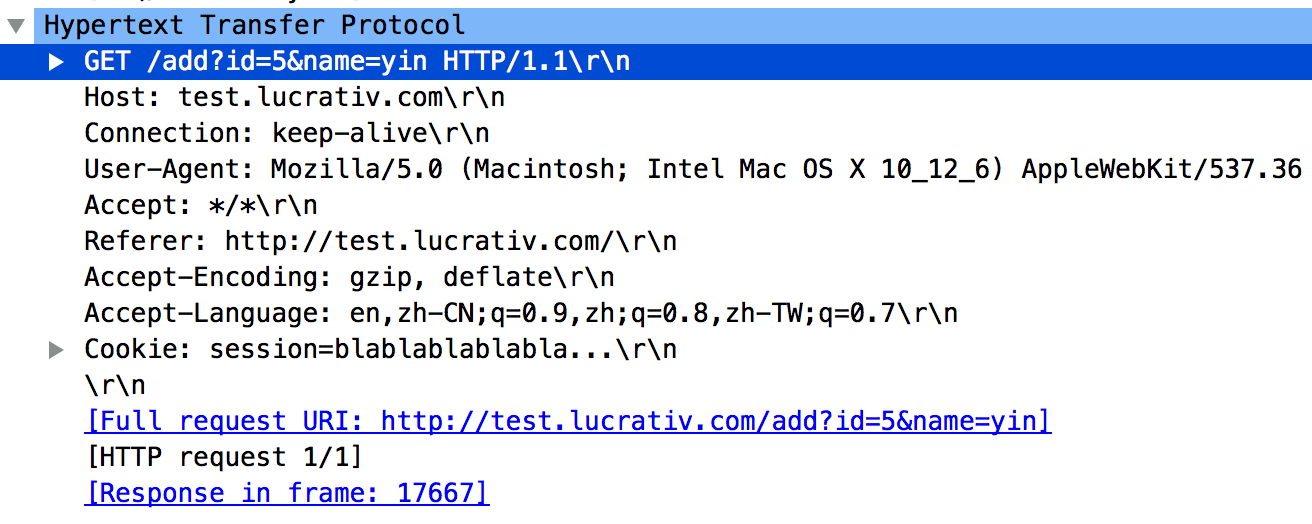
可以看到,使用地址栏访问的和使用ajax的get请求本质上都是一样的,只是使用ajax我们可以设置http请求头,而使用地址栏访问的是由浏览器添加默认的请求头。
上面是使用http抓的包,我们可以看到请求的完整url,包括请求的参数,而如果是抓的https的包的话,GET放在url上的参数就看不到了:
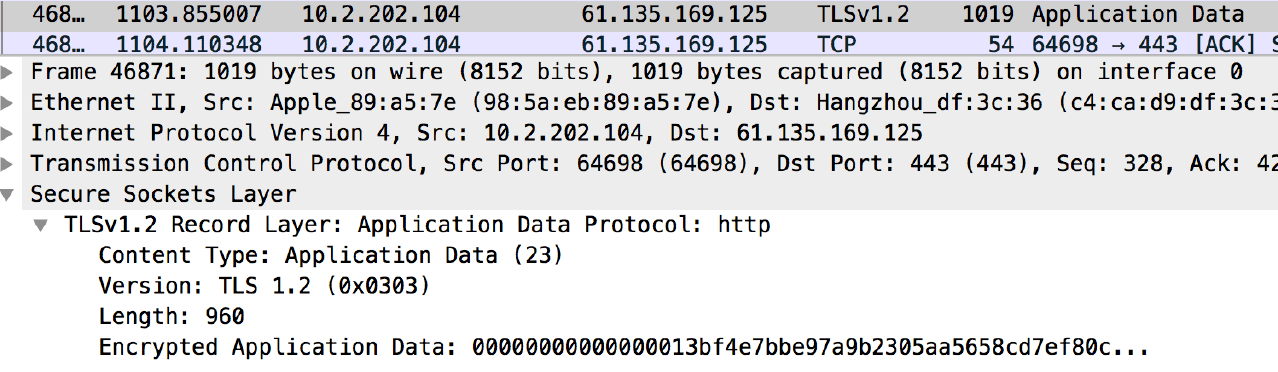
也就是说https的请求报文是加密的,包括请求的uri等,需要解密后才能看到。那是不是说使用https的GET也是安全的,而不是https的POST不会比GET安全?
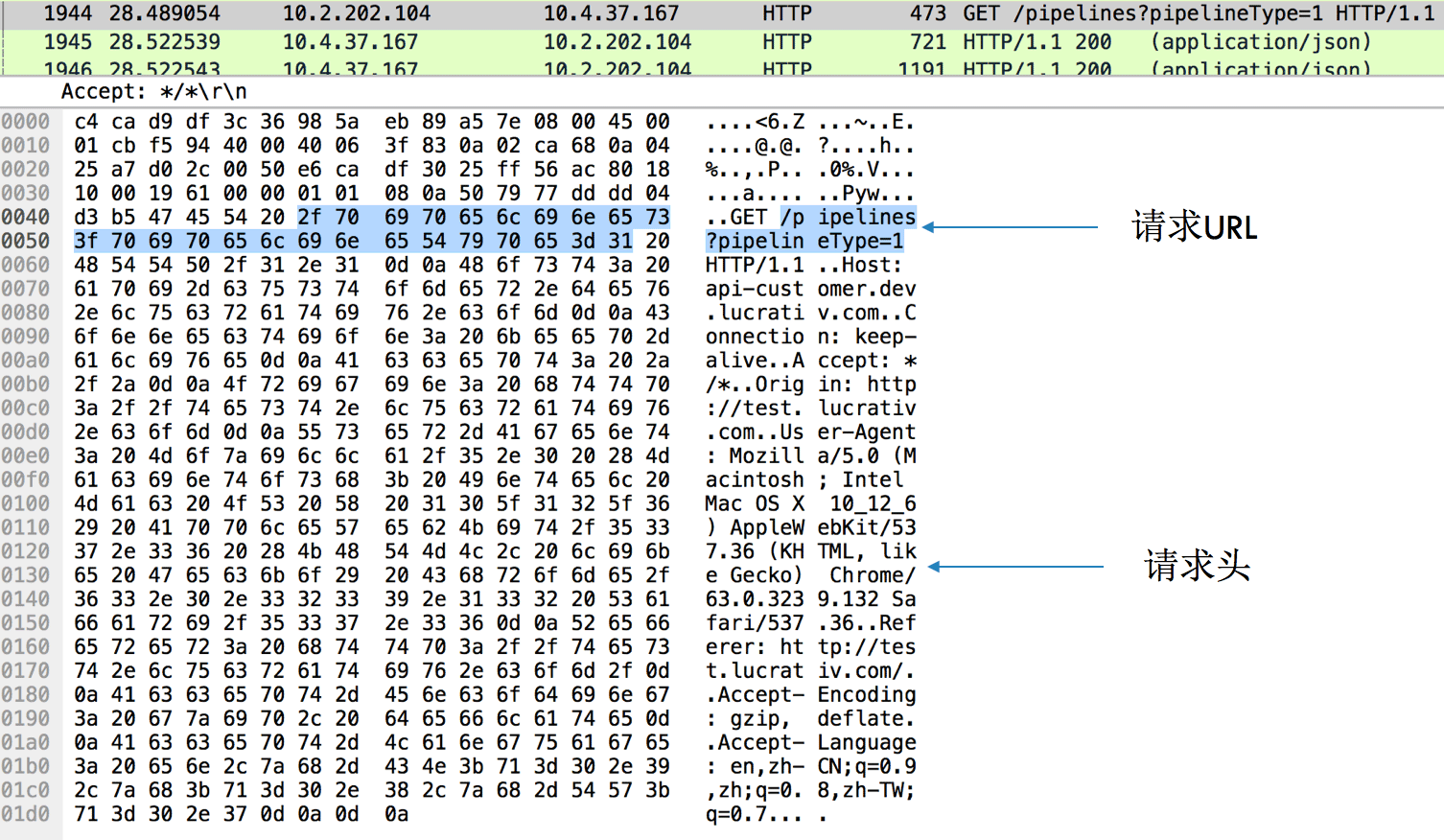
我们先来看一下http的请求报文,如下图所示:

如果使用抓包工具的话,可以看到请求报文确实是按照上图排列的,如图所示的GET:
而POST是这样的:
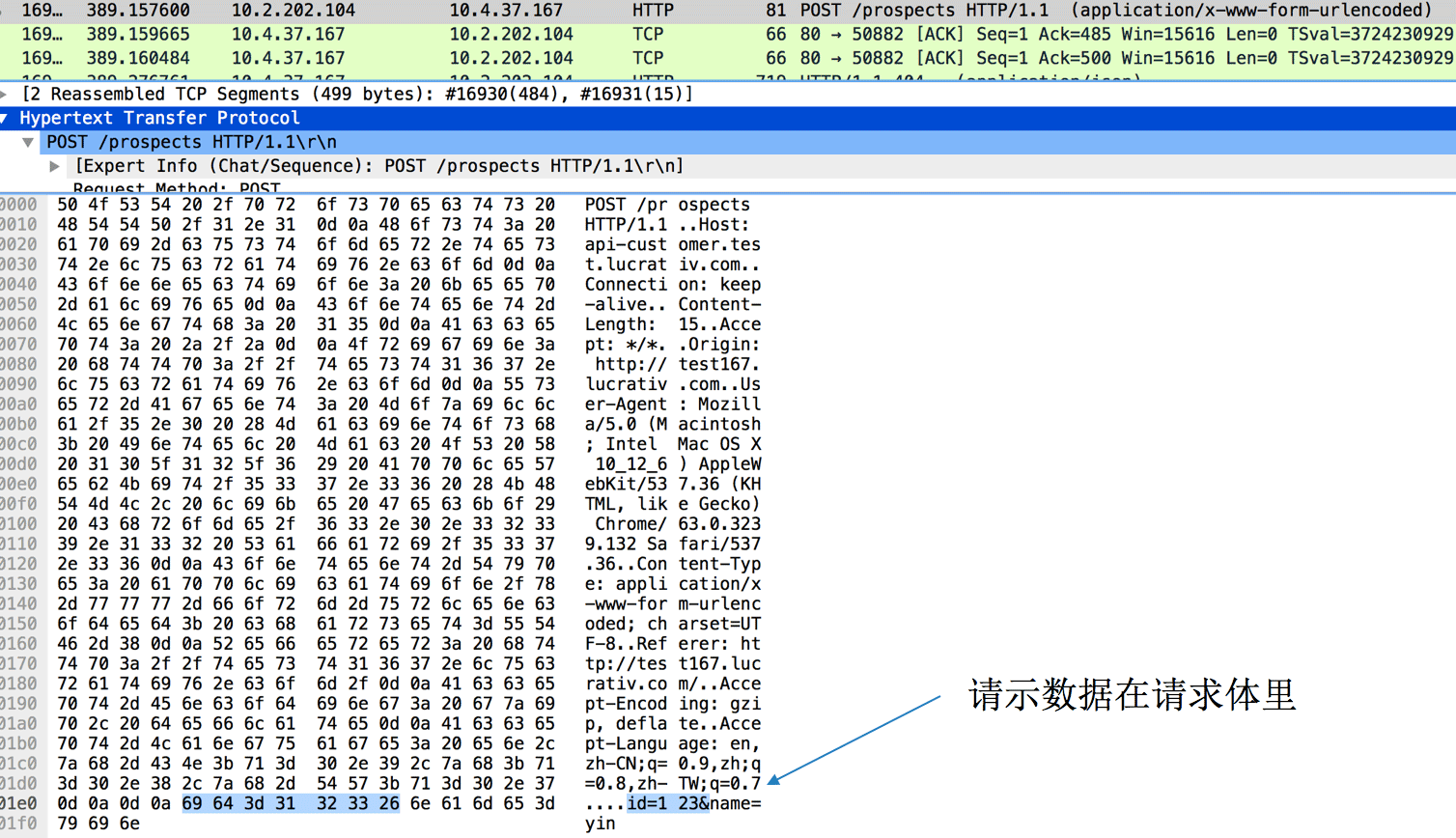
所以本质上GET/POST是一样的,只是GET把数据拼到url,而POST是放到请求体。另外一点,url是有长度限制的,包括浏览器和接收的服务如nginx,而请求体是没有限制的(浏览器没有限制,但是一般nginx接收会有限制),还有POST的数据支持多种编码格式。
虽然如此,POST还是比GET安全的,体现在以下几点:
- GET参数是放在url上面,用户可以保存为书签、传播链接,如果参数有敏感数据,如登陆的密码,那么可能会泄露
- 搜索引擎在爬取网站的时候如果修改数据库的请求支持GET,那么很可能数据库会无意被搜索引擎修改
- script/img等标签是GET请求,会更加方便跨站请求伪造,在浏览器地址栏输入也是GET,也是为修改请求提供便利
接着讨论请求响应状态码。很多人都知道200、404、500这几个,对于其它的可能就不甚了解了。这里我把一些常用的状态码列一下。
1. 301 永久转移
当你想换域名的时候,就可以使用301,如之前的域名叫www.renfed.com,后来换了一个新域名www.rrfed.com,希望用户访问老域名的时候能够自动跳转到新的域名,那么就可以使用nginx返回301:
|
1 2 3 4 5 6 |
server { listen 80; server_name www.renfed.com; root /home/fed/wordpress; return 301 https://www.rrfed.com$request_uri; } |
浏览器收到301之后,就会自动跳转了。搜索引擎在爬的时候如果发现是301,在若干天之后它会把之前收录的网页的域名给换了。
还有一个场景,如果希望访问http的时候自动跳转到https也是可以用301,因为如果直接在浏览器地址栏输入域名然后按回车,前面没有带https,那么是默认的http协议,这个时候我们希望用户能够访问安全的https的,不要访问http的,所以要做一个重定向,也可以使用301,如:
|
1 2 3 4 5 6 7 8 |
server { listen 80; server_name www.rrfed.com; if ($scheme != "https") { return 301 https://$host$request_uri; } } |
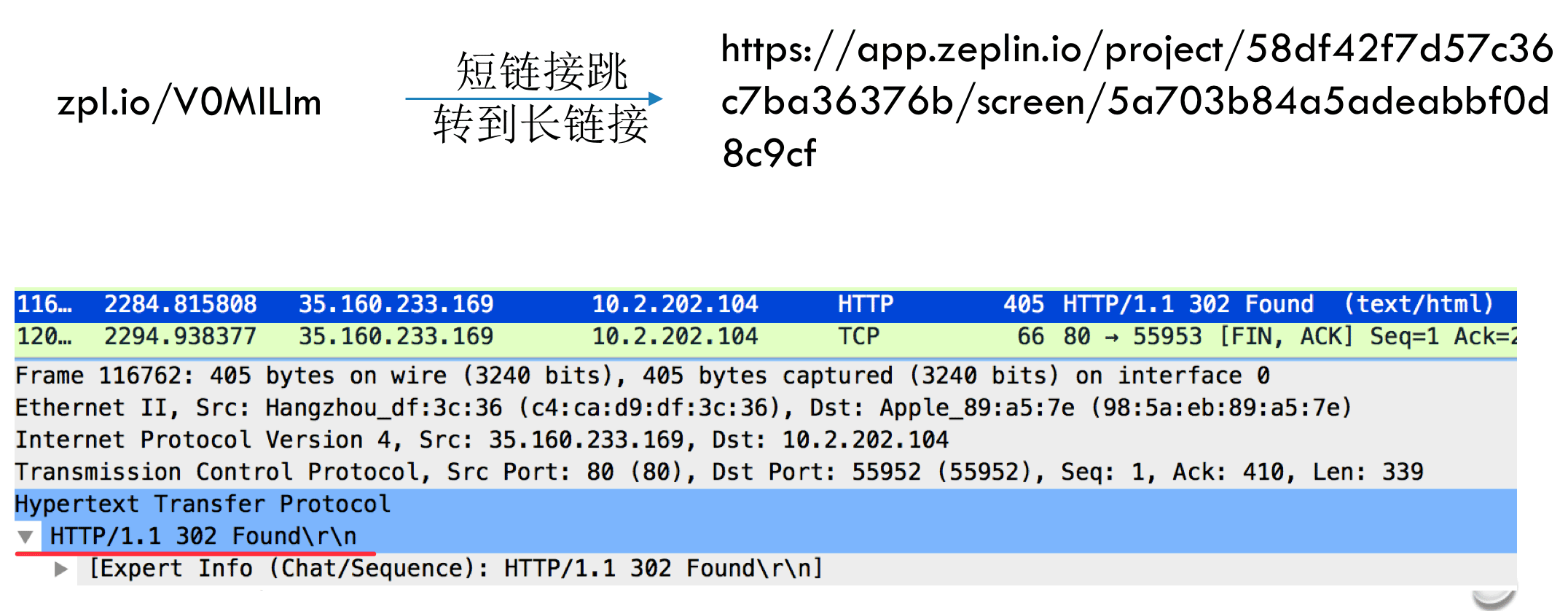
2. 302 Found 资源暂时转移
很多短链接跳转长链接就是使用的302,如下图所示:
3. 304 Not Modified 没有修改
在本地使用webpack-dev-server开发的时候,如果没有改js/css,那么刷新页面的时候请求本地的js/css文件将返回304,如下图所示:
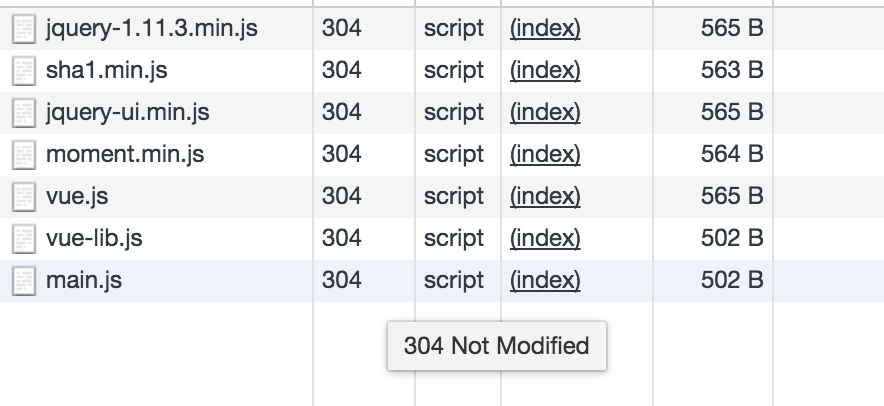
webpack-dev-server的服务怎么知道没有修改呢,因为浏览器在请求的时候带上了etag,如:
W/”10e632-Oz38I6asQyS459XpsaJYkjMUoZI”
服务会计算当前文件的etag,它是一个文件的哈希值,然后比较一下传过来的etag,如果相等,则认为没有修改返回304。如果有修改的话就会返回200和文件的内容,并重新给浏览器一个新的etag。下次请求的时候浏览器就会带上这个新的etag。如果把控制台的disable cached打开的话,那么浏览器即使有etag也不会带上。另外一个判断有没有修改的字段是Last Modified Time,这是根据文件的修改时间。
4. 400 Bad Request 请求无效
当必要参数缺失、参数格式不对时,后端通常会返回400,如下图所示:

并带上了提示信息:
{“message”:”opportunityId type mismatch required type ‘long’ “}
通过400可以知道请求参数有误,结合提示信息,说明需要传一个数字,而不是字符串。
5. 403 Forbidden 拒绝服务
服务能够理解你的请求,包括传参正确,但是拒绝提供服务。例如,服务允许直接访问静态文件:

但是不允许访问某个目录:
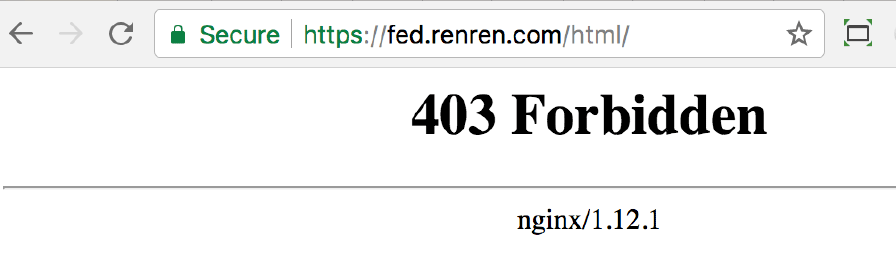
否则,别人对你服务器上的文件就一览无遗了。
403和401的区别在于,401是没有认证,没有登陆验证之类的错误。
6. 500 内部服务器错误
如业务代码出现了异常没有捕获,被tomcat捕获了,就会返回500错误:

如:数据库字段长度限制为30个字符,如果没有判断直接插入一条31个字符的记录,就会导致数据库抛异常,如果异常没有捕获处理,就直接返回500。
当服务彻底挂了,连返回都没有的时候,那么就是502了。
7. 502 Bad Gateway 网关错误
如下图所示:
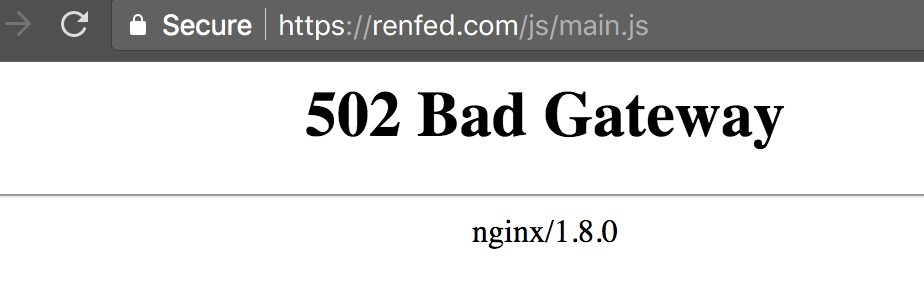
这种情况是因为nginx收到请求,但是请求没有打过去,可能是因为业务服务挂了,或者是打过去的端口号写错了:
|
1 2 3 4 5 6 |
server { location / { # webpack的服务 proxy_pass https://127.0.0.1:7071; } } |
nginx返回了502.
8. 504 Gateway Timeout 网关超时
通常是因为服务处理请求太久,导致超时,如PHP服务默认的请求响应最长处理时间为30s,如果超过30s,将会挂掉,返回504,如下图所示:

这种情况可能是因为服务还要请求第三方的服务,第三方服务处理时间较久没有返回,如在向FCM发送Push的时候,如果一个请求里面需要发送的订阅的浏览器(subscriptions)太多了,就经常会处理很久,导致504.
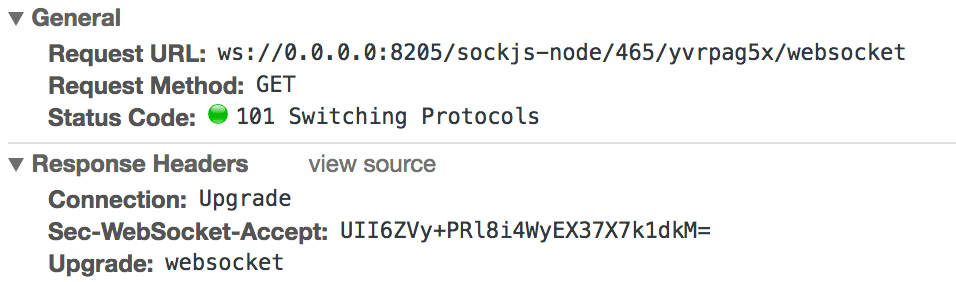
9. 101 协议转换
websocket是从http升级而来,在建立连接前需要先通过http进行协议升级:
还有一个600,600是一种不太常用的状态码,表示服务器没有返回响应头部,只返回实体内容。
这些状态码实际上就是一个数字,可以任意返回,但是最好是按照http的规定返回合适的状态码。如果返回4、5、6开头的http状态码,浏览器将会打印错误,认为当前请求失败。
我们还没有说怎么判断请求成功了,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
xhr.open("POST", UPLOAD_URL); xhr.onreadystatechange = function() { // readyState为4表示请求完成 if (this.readyState === 4){ if (this.status === 200) { let response = JSON.parse(this.responseText); if (!response.status || response.status.code !== 0) { // 失败 callback.failed && callback.failed(); } else { // 成功 callback.success(response.data.url); } } else if (this.status >= 400 || this.status === 0) { // 失败 callback.failed && callback.failed(); // 正常不应该返回20几的状态码,这种情况也认为是失败 } else { callback.failed && callback.failed(); } } }; xhr.send(formData); |
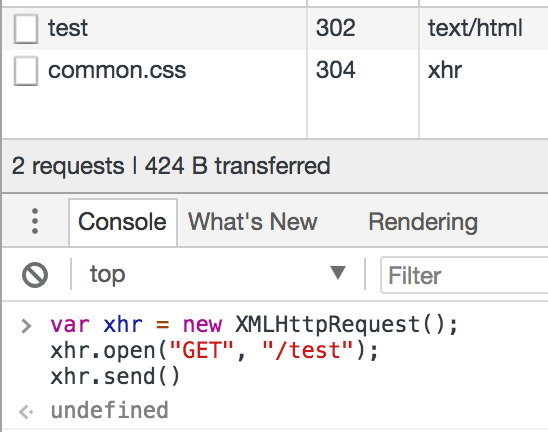
这里有个问题,如果返回的状态码是3开头的重定向,需要自己再去发一个请求吗?
实践证明,不需要,浏览器会自动重定向,如下图所示:
最后,本文提到了3种常用的请求编码,分别是application/www-x-form-urlencoded、application/json、multipart/form-data,第一种是最常用的一种,适用于GET/POST等,第二种常见于请求响应的数据格式,第三种通常用于上传文件。然后还比较了POST和GET,虽然两者的请求数据都在http报文里面,只是位置不一样,但是考虑到用户、搜索引擎等使用场景,POST还是会比GET更安全。最后说了几个常用的http状态码,并用一些实际的例子加深印象和理解。
目录: 基础技术
好文!
好文!